In the last week, a single Medium article set LinkedIn, Reddit, and Hacker News ablaze. Its title: “RAG is DEAD! And why that’s the best news you’ll hear all year.” The argument was simple: million-token context windows and agentic AI have made retrieval-augmented generation obsolete. By May 2026, the piece claimed, RAG would join the scrapheap of last-generation AI architecture.
It’s a compelling, almost seductive narrative. And it’s wrong.
Not subtly wrong. Not “technically correct but missing nuance” wrong. It’s 100%, demonstrably, data-backed wrong. And the consequences of believing it could cost your enterprise millions in hallucination-ridden outputs, stale answers, and ballooning inference bills. So let’s address the elephant in the server room: is RAG actually dying, or is something much more interesting happening?
The reality is that RAG isn’t dead. It’s evolving into an essential backbone that makes agentic AI trustworthy, efficient, and grounded in fresh, private data. I’ll steel-man the “RAG is dead” argument, then dismantle it with three facts its proponents ignore, the data that proves RAG remains essential, and a concrete framework for building retrieval systems that won’t just survive the next hype cycle, they’ll thrive through it.
The “RAG Is Dead” Argument, Steel-Manned
Let’s be fair. The dismissers aren’t pulling their claims from thin air. The core case, as I’ve gathered from that viral piece and the debates it sparked, rests on three legs.
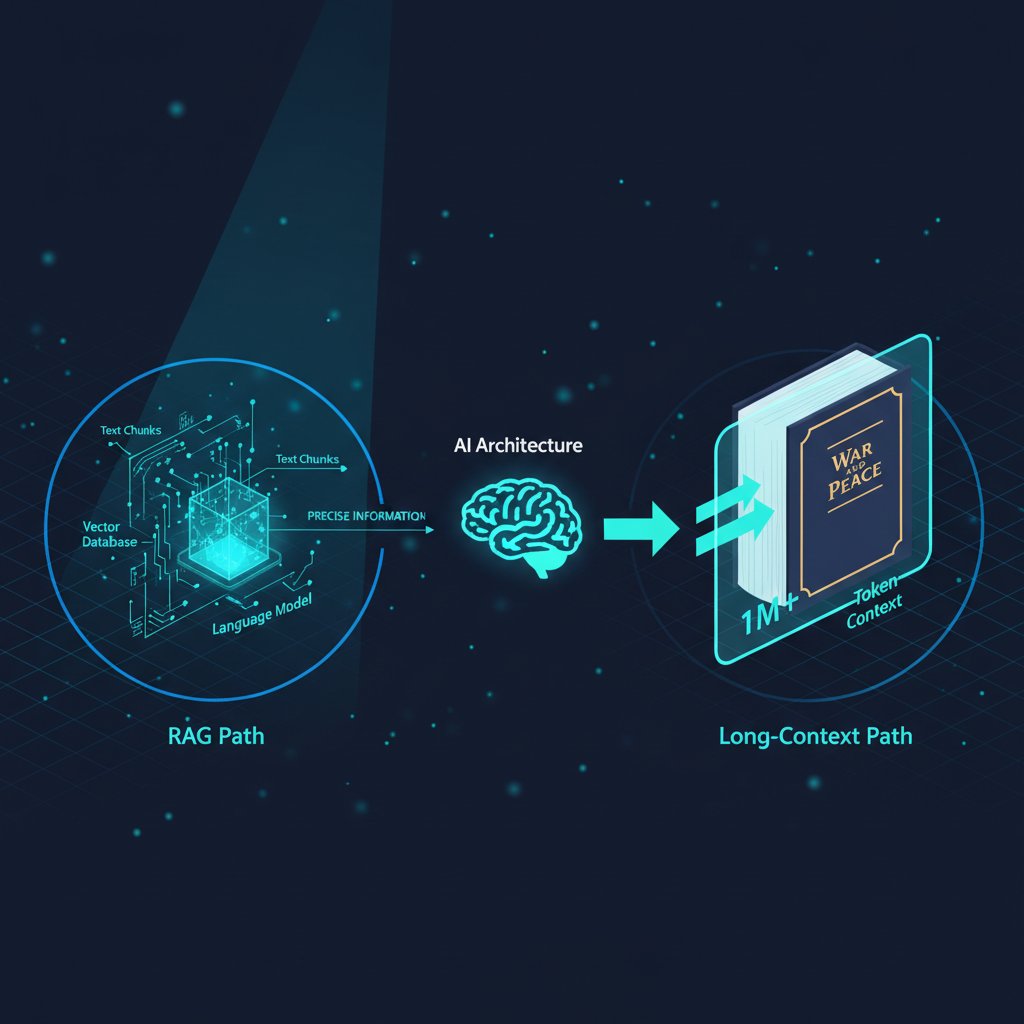
First, context windows have exploded. Gemini 1.5 Pro now handles 2 million tokens; Claude and GPT-4 variants handle hundreds of thousands. If you can stuff your entire knowledge base into a prompt, why bother with a separate retrieval pipeline? Retrieval adds latency, complexity, and points of failure. In a world of effortless mega-prompts, RAG looks like technical debt.
Second, agentic AI systems, those that reason, plan, and take multi-step actions, are increasingly handling their own information gathering. Why pre-retrieve documents when an agent can search the web, query a database, or call an API in real time? The argument is that retrieval is being absorbed into the agent’s reasoning loop, making standalone RAG pipelines redundant.
Third, the hallucination problem hasn’t been solved by RAG. Skeptics point to studies showing that even with perfect retrieval, models sometimes ignore the provided context or overly rely on their parametric knowledge. If RAG doesn’t eliminate hallucination, and long-context models are getting better, why pay the integration tax?
These aren’t stupid arguments. They’re the right questions to ask. But they all share a common blind spot: they compare a mature, optimized technology (long-context LLMs) to a straw-man version of RAG that nobody serious is actually building in 2025.
What the Death Proponents Are Missing
Three inconvenient facts never make it into the hot-take Medium posts.
Million-token models aren’t free or fast
Stuffing 2 million tokens into a prompt doesn’t just test the model’s attention mechanism. It demolishes your latency budget and your cloud bill. The transformer’s quadratic attention cost means that processing 1 million tokens isn’t 10x the cost of 100k, it can be 100x. At current pricing, a single query against a multi-million-token context can cost dollars, not cents. Multiply that by thousands of daily queries, and you’re looking at a seven-figure annual bill for what a well-tuned RAG system can do for a tenth of the price.
As the engineers on r/LocalLLaMA keep reminding newcomers: “The bottleneck isn’t what the model can hold. It’s what you can afford to send.” Enterprise RAG retrieves only the most relevant chunks, maybe 5,000 tokens instead of 2 million. That’s the difference between a Prius and a cargo plane for your daily commute.
Enterprises are doubling down on RAG, not abandoning it
If RAG were dead, someone forgot to tell the Fortune 500. In January 2026, Henkel, the global innovation giant, partnered with Squirro to deploy a RAG-based knowledge management system that streamlined over 300,000 search results for internal teams. This wasn’t a science experiment. It was a production deployment at a company that runs on operational efficiency.
Meanwhile, the Onyx AI Buyer’s Guide, released this month, profiles 11 enterprise RAG platforms with detailed pricing models, deployment options, and real customer case studies. The very existence of a mature, multi-vendor market signals one thing: enterprises are actively buying, building, and scaling RAG. They aren’t waiting for the next context-window leap. They need solutions now that work with their existing access-control policies, data freshness requirements, and budget constraints.
And then there’s the award that should have been headline news. Progress (Nasdaq: PRGS) just took home the 2026 AI Excellence Award for its Agentic RAG solution. Not a “generative AI” award. Not “best chatbot.” Specifically, Agentic RAG. The industry is voting with its dollars and its recognition that the future of enterprise AI has retrieval at its core.
Agentic AI enhances RAG, it doesn’t replace it
This is the crucial nuance the “RAG is dead” crowd misses. Agentic AI doesn’t make retrieval obsolete; it makes retrieval better. A static RAG pipeline that chunks, embeds, retrieves, and generates in a single pass is indeed limited. But an agentic RAG system, where an AI agent decides what to retrieve, formulates multiple queries, evaluates the retrieved context, and iterates, is a completely different beast.
As AI engineer Pulkit noted on LinkedIn, “RAG systems must evolve beyond single-shot retrieval.” He’s right. But evolution isn’t extinction. It’s the same way cars didn’t kill the wheel; they made it essential in a more complex system. Agentic RAG uses retrieval as a tool in a reasoning toolkit, not as a one-and-done step.
RAG Isn’t Dying—It’s Evolving Into Something Bigger
The real story isn’t about death. It’s about a spectrum.
On one end, you have traditional single-shot RAG: embed, index, retrieve, answer. It works well for simple FAQ bots and document Q&A where latency must be minimal and cost is a primary concern. On the other end, you have fully autonomous agents that can browse the web, query databases, and run code, but at dramatically higher cost, latency, and unpredictability.
Between them lies the sweet spot where enterprise value is exploding: agentic RAG. This is the architecture Progress won its award for. It’s what Squirro built for Henkel. It’s what I see winning in production across industries.
In an agentic RAG system, the LLM doesn’t just receive retrieved chunks; it actively participates in the retrieval process. It can decompose a complex question into sub-queries, retrieve information for each, synthesize the results, notice gaps, and issue follow-up retrievals, all while staying grounded in approved, auditable data. That’s the kind of system that will define the next decade of enterprise AI.
So if you’re building AI that needs to be accurate, cost-effective, and trustworthy, don’t throw out retrieval. Evolve it. The data shows that RAG isn’t going anywhere, it’s becoming the foundation for the next wave of intelligent systems. Let’s talk about how agentic RAG can work for your data.