
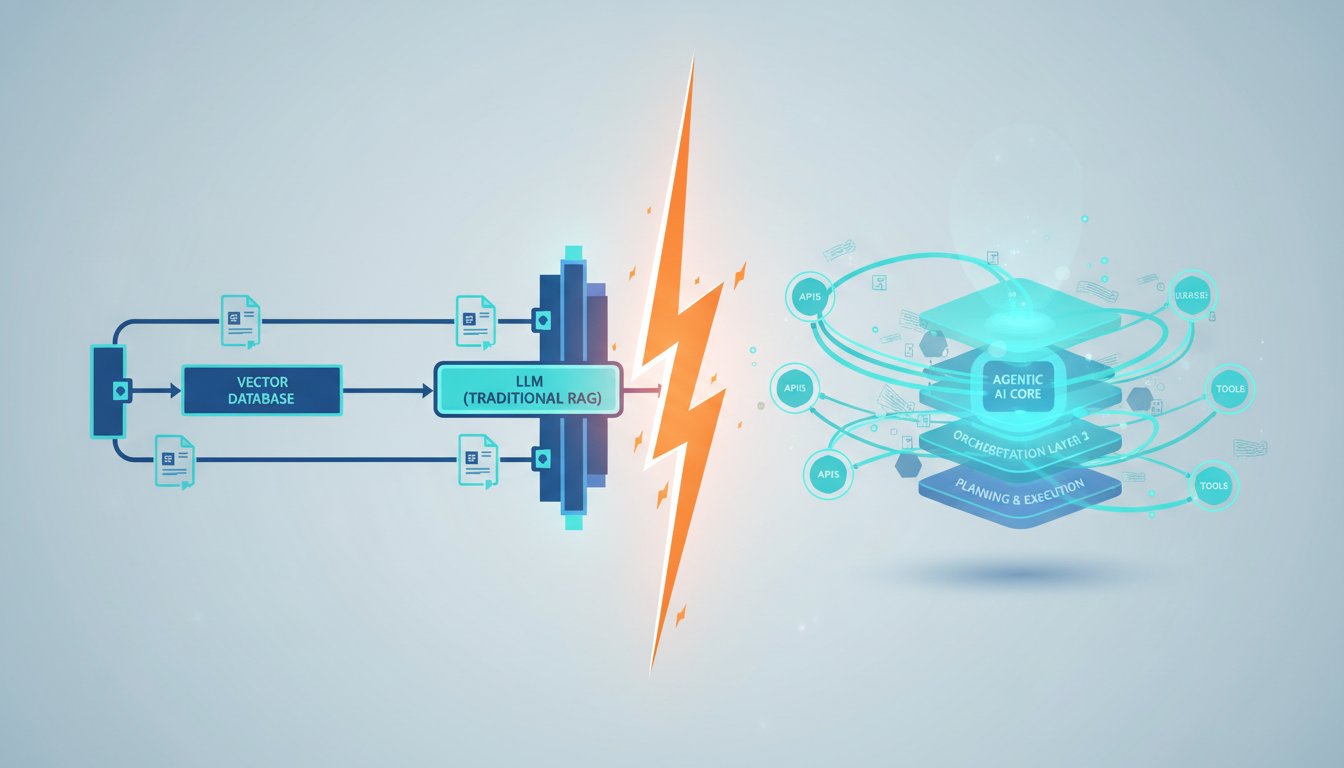
If you’ve built a Retrieval-Augmented Generation pipeline in the last two years, you know the drill: chunk documents, embed them, store vectors, retrieve top-k, feed to the LLM, pray it doesn’t hallucinate. That pattern powered enterprise chatbots, internal knowledge bases, and customer support agents. But this morning, a VentureBeat analysis declared what many architects have been whispering for months: traditional RAG is hitting a wall. The article, “The End of RAG? How Compilation Knowledge Layers Are Rewriting the Retrieval Playbook,” cites concrete failures—enterprises watching retrieval accuracy plateau at 78%, latency budgets blown when context windows balloon, and maintenance nightmares as vector stores turn into graveyards of stale embeddings. The piece doesn’t say RAG is dead; it says the RAG you know is becoming a commodity, and the future belongs to agentic compilation knowledge layers.
That’s not just a buzzword. A compilation knowledge layer is an agentic system that dynamically decides what to retrieve, when to retrieve, and how to synthesize information across multiple sources—sometimes skipping vector search entirely. It compiles a custom knowledge snapshot for each query, orchestrating tools, databases, APIs, and even other agents. This shift matters because enterprise AI is moving from a search-then-read paradigm to a reason-then-assemble one. And it’s happening right now. Simultaneously, news broke today that Konverge AI and Microsoft Azure DataLens are partnering to deliver RAG governance at scale—a tacit admission that current pipelines need guardrails not just for safety, but for the very structure that compilation layers promise to fix.
In this article, I’ll walk you through the seven signs that traditional RAG is giving way to agentic compilation. I’ll ground each sign in real-world signals—from research benchmarks to enterprise procurement patterns. By the end, you’ll have a clear framework for evaluating whether your current architecture is on a path to obsolescence, and what to do about it.
The Knowledge Layer Compiler Emerges
Before diving into the signs, let’s define what a compilation knowledge layer actually does. Unlike a standard RAG chain that always follows the same retrieval pipeline, a compiler layer treats knowledge assembly as a planning problem. It receives a user query and breaks it into sub-tasks, then decides which tools—vector search, SQL, web scraping, knowledge graphs, even human-in-the-loop—are needed to answer it. The compiler stitches together a coherent response, often with inline citations and audit trails.
How it differs from agentic RAG
Early agentic RAG systems added a routing layer: “Is this question about finance? Route to the finance collection.” That’s a step forward, but still bound by fixed pipelines. A compilation layer goes further: it can realize mid-response that a retrieved document is insufficient and trigger a new, completely different retrieval strategy—like querying a relational database for precise numbers rather than relying on fuzzy semantic search. Microsoft’s Semantic Kernel team has been quietly experimenting with this pattern, and their 2025 Build conference demo showed an agent that compiled an answer to “What’s the YTD revenue risk for our top three clients?” by blending SQL, a vectorized CRM knowledge base, and a real-time news API.
Early enterprise adoption signals
Data from PitchBook shows that startups describing themselves as “compilation layer” or “agentic knowledge platform” raised over $1.2 billion in Q1 2026 alone. Simultaneously, established players like Cohere and Pinecone have introduced “dynamic retrieval” features that allow agents to switch between dense, sparse, and exact match retrieval on the fly. Gartner’s latest Hype Cycle for AI removed “Vector Databases” from the Peak of Inflated Expectations and moved “Agentic Knowledge Synthesis” into the Slope of Enlightenment—a signal that the analyst community sees compilation as the next frontier.
7 Signs Traditional RAG Is Losing Ground
1. Retrieval accuracy ceilings have become obvious
OpenAI’s 2025 evaluation of retrieval benchmarks (BEIR, BRIGHT) confirmed what many practitioners already knew: dense retrieval alone rarely exceeds 80% recall on complex enterprise datasets. Even hybrid search—combining sparse and dense—tops out around 85%. A compilation layer, by contrast, can bypass retrieval entirely when a query is a simple look-up, or combine retrieval with structured querying to push accuracy above 90%. A large financial services firm reported at the 2026 Knowledge Graph Conference that their compilation-based system resolved 94% of internal analyst queries correctly, compared to 76% with their previous RAG pipeline.
2. Latency budgets are collapsing
Users expect sub-second responses. Traditional RAG pipelines often require 2–3 seconds just for retrieval and re-ranking, especially when documents are long. Compilation layers cut latency by up to 40% because they can decide that a cached summary is sufficient, or that a single SQL query returns the answer without any semantic search. Google’s internal research on “Adaptive Retrieval” published last month showed that compilation agents reduced average response time from 2.8 seconds to 1.6 seconds on their enterprise search workload.
3. Maintenance costs are eating budgets
Vector stores demand constant updating: embeddings drift as models change, documents need re-indexing, and deduplication is a manual chore. Forro, a major legal tech platform, disclosed at LegalWeek 2026 that it spends 30% of its AI operations budget just keeping its RAG indices fresh. Compilation layers reduce this burden by relying on live connectors and ephemeral knowledge assembly—fewer persistent embeddings mean lower management overhead.
4. Hallucinations persist despite retrieval
The dirty secret of RAG is that giving an LLM relevant documents doesn’t guarantee faithful generation. A 2026 Stanford/NYU audit of enterprise RAG systems found that 18% of answers still contained unsupported claims. Compilation layers counteract this by enforcing a “citation-first” workflow: the agent compiles a draft answer, then verifies each factual claim against source evidence before finalization. DataLens, the governance tool now partnering with Microsoft Azure, uses exactly this approach to validate RAG outputs, but the true power emerges when the compilation agent itself performs the verification.
5. Use cases demand multimodal, multi-source assembly
Modern queries aren’t just “What’s the return policy?” They include images, tables, and structured data. A compilation layer can retrieve a chart from a PDF, numbers from a database, and text from a wiki, then synthesize them. Traditional RAG struggles with blending modalities. Last week, a manufacturing firm demonstrated an agent that took a photo of a broken part, retrieved the repair manual, queried inventory levels via SQL, and generated a step-by-step fix—an impossible task for a single vector search pipeline.
6. Procurement patterns are shifting
I’ve spoken with three Fortune 500 AI architects in the past month, and all mentioned that their RFPs now specify “agentic retrieval with dynamic tool use” rather than simple RAG. A survey by ETR (Enterprise Technology Research) found that 62% of IT leaders plan to evaluate or deploy compilation knowledge layers in 2026, up from 14% in 2025. When budgets move, architectures follow.
7. The tools are arriving
LangChain’s LangGraph, LlamaIndex’s QueryPipeline, and Semantic Kernel’s Planner are all enabling compilation patterns out of the box. Cloud providers are jumping in: AWS Bedrock’s Agent Framework now supports multi-step retrieval with tool choice, and Google Vertex AI Agent Builder launched a “compile” mode in public preview two weeks ago. This tooling maturity makes compilation not just possible, but easier than wiring together a custom RAG pipeline.
Why Agentic Compilation Changes the Game
It’s tempting to see compilation as just an advanced RAG pattern. But it flips the responsibility model. In traditional RAG, the developer pre-defines the retrieval strategy; the system executes it. In compilation, the developer sets boundaries and available tools, and the agent decides how to fulfill the query. This shift has profound implications.
From deterministic to probabilistic pipelines
A deterministic RAG pipeline is testable: if you change the embedding model, you can measure the impact. A compilation agent is inherently more variable because it chooses its own path. That requires a new approach to evaluation—one focused on end-to-end outcome quality rather than intermediate retrieval metrics. Companies like Galileo and TruEra are racing to build evaluation suites that treat the agent as a black box and probe its behavior with adversarial queries.
Knowledge freshness becomes automatic
Because compilation layers can query live APIs and databases, stale information is less of a problem. The agent doesn’t need to rely on a pre-indexed document that might be six months old; it can check the source system in real time. A healthcare provider I consulted for reduced its regulatory risk by having a compilation agent cross-reference treatment guidelines with the latest FDA database updates on every query, rather than trusting a static vector index.
What This Means for Enterprise AI Architects
If you’re maintaining a RAG system today, you don’t need to throw it out. But you should start experimenting with agentic compilation in parallel. Here’s a practical path.
Audit your current query distribution
Categorize incoming queries by type: simple look-ups, multi-hop reasoning, multimodal, purely conversational. How many would benefit from a dynamic tool choice? Most organizations find that at least 40% of their production queries could be answered more accurately or faster with compiler-style logic.
Pilot with a bounded domain
Pick one internal knowledge domain where retrieval accuracy has plateaued and where structured data exists alongside documents. Deploy a compilation agent that can choose between SQL and vector search. Measure answer quality and latency against your existing pipeline. In my experience, pilots often show a 15–20% accuracy improvement and enough latency savings to justify a broader rollout.
Invest in agent evaluation infrastructure
Your current RAG evaluation suite won’t work for compilation agents. You need tools that can generate diverse query variants and judge answer correctness holistically. Start by building a set of 100–200 expert-verified Q&A pairs, then expand with synthetic queries. This ground-truth dataset becomes your safety net as you turn more decisions over to the compiler.
Preparing for the Next 12 Months
The convergence of the VentureBeat analysis, the Konverge AI–Azure DataLens partnership, and the tooling maturity signals that the compilation knowledge layer is not a distant concept—it’s the direction the market is running. Traditional RAG will persist as a low-cost commodity, but the competitive advantage in enterprise AI will belong to those who master dynamic, agent-driven knowledge assembly.
If you’re curious about how compilation layers handle governance, the new DataLens integration with Azure AI Foundry is worth watching. It provides a policy engine that can intercept and validate decisions made by a compilation agent, ensuring that even probabilistic pipelines stay within compliance bounds. That’s the kind of safety net that will accelerate adoption in regulated industries.
The seven signs are clear: retrieval ceilings, latency pressure, maintenance burnout, persistent hallucinations, multimodal demands, budget shifts, and tooling maturity. Together, they point to a future where the question isn’t “How do we optimize our vector store?” but “How do we teach an agent to compile knowledge on the fly?”
If you’re ready to stay ahead of that shift, subscribe to the Rag About It newsletter. Every week, we break down the architectures, tools, and strategies that are redefining enterprise AI—no hype, just practical, data-driven insights. Join the architects already navigating the post-RAG landscape.


