
Category: RAG Evaluation
-

7 RAG Accuracy Gaps Exposed by New Enterprise Benchmark
When a Fortune 500 healthcare company audited its retrieval-augmented generation (RAG) pipeline recently, it found something alarming: 43% of the system’s answers to complex clinical questions had subtle but dangerous errors. The retrieval engine pulled the right studies, the language model produced fluent, confident responses, but the answers were wrong in ways the existing evaluation…
-

5 RAG Compliance Metrics That Catch 72% of Hallucinations
In late May 2026, a European banking consortium made headlines for all the wrong reasons. Their customer-facing RAG chatbot, rolled out across seven countries, became the first high-profile AI system to be fined under the freshly enforced EU AI Act. The penalty wasn’t for a catastrophic meltdown or a privacy leak. It was for persistent,…
-

7 New RAG Evaluation Metrics That Catch Hidden Accuracy Gaps
You just deployed a retrieval-augmented generation system that passed every accuracy test in your evaluation suite. The demo wowed stakeholders. The pilot ran flawlessly. Yet three weeks into production, customer complaints start trickling in: the chatbot insists the warranty covers water damage, and the legal assistant invented a nonexistent clause. The traditional metrics, BLEU, ROUGE,…
-

Open-Source RAG Benchmark Reveals Hidden Enterprise Gaps
Imagine deploying an AI system that retrieves the right documents 95% of the time, only to discover it fabricates claims in one out of every three responses. For enterprise teams betting on retrieval-augmented generation (RAG) to power customer support, legal research, and medical insights, that nightmare became measurable last week when Cohere quietly open-sourced a…
-
7 Enterprise RAG Audit Failures You Should Know
If you deployed a retrieval-augmented generation system this year, you probably think you’ve crossed the last big hurdle to production AI. The vendor demos looked flawless. The proof-of-concept answered every internal knowledge-base query with crisp, cited responses. Legal even signed off on the guardrails. But a sobering new audit, released on May 8, 2026 by…
-

The Measurement Paradox: Why Your RAG Metrics Are Tracking Success While Your System Fails
Your RAG system shows 95% retrieval accuracy in testing. Your precision metrics are stellar. Your NDCG scores would make any ML engineer proud. Yet somehow, three months into production, your enterprise RAG deployment is quietly collapsing—and your dashboards never saw it coming. This is the measurement paradox that’s plaguing enterprise RAG deployments in 2024: the…
-
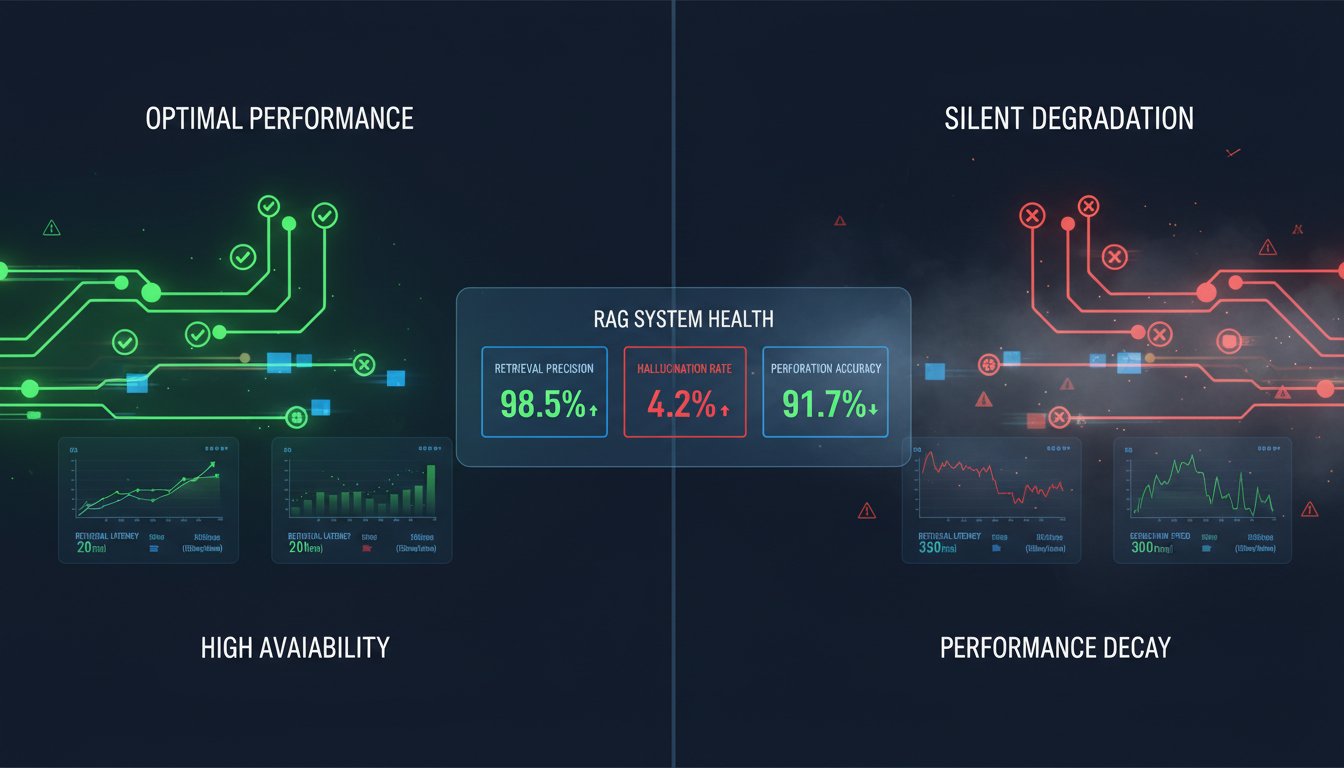
The RAG Measurement Framework: How to Evaluate What Actually Matters in Production
Imagine deploying a RAG system that feels like it’s working perfectly—your LLM generates coherent responses, your retrieval returns relevant documents, and your team ships it to production confident in the outcome. Six months later, you discover a silent degradation: retrieval precision has dropped 15%, hallucination rates are climbing, and your users are quietly getting worse…