
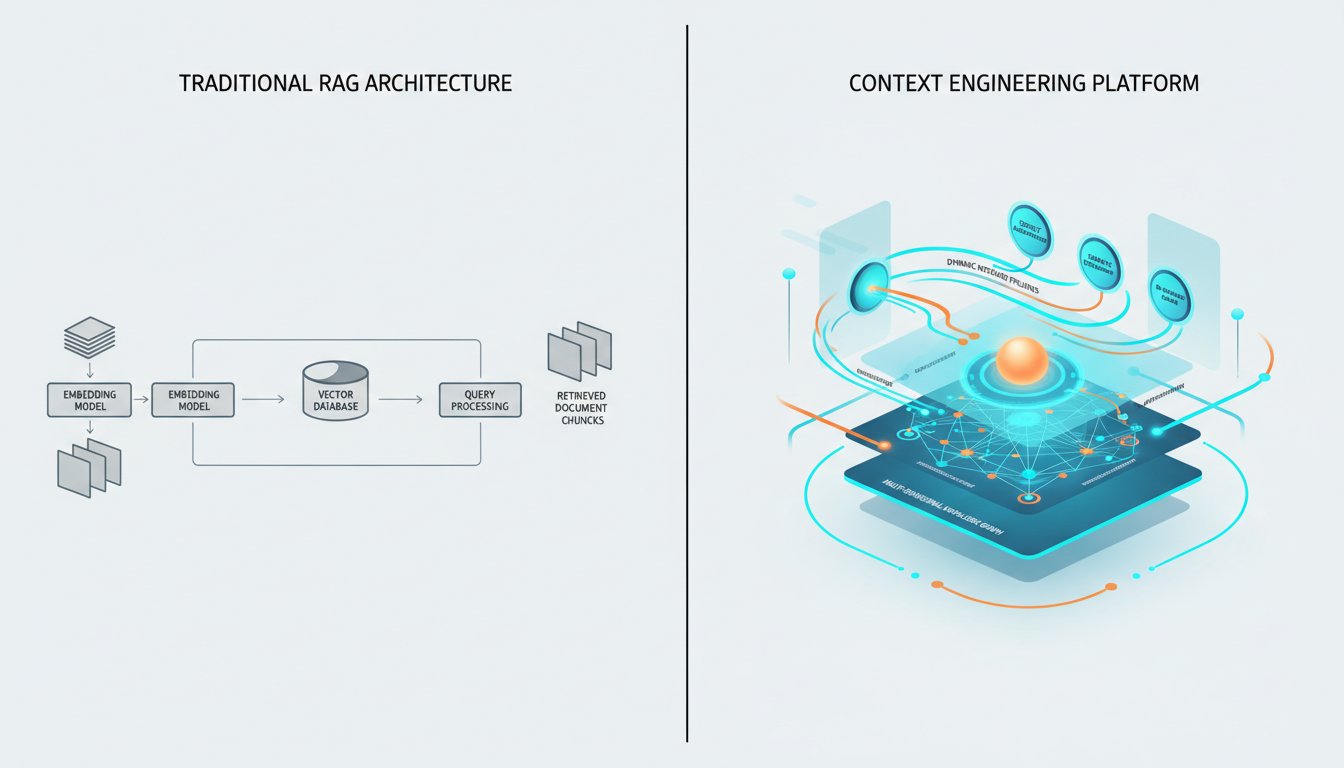
The enterprise AI scene is shifting fast. For the past two years, Retrieval Augmented Generation has been the default answer to a simple question: how do we get AI systems to access our private data? The answer was RAG. Embed your documents, build a vector database, retrieve the most relevant chunks, and feed them to the language model. It worked, mostly. But a new paradigm is emerging that makes this approach look like a prototype rather than a production system.
Gartner has declared 2026 “the year of context,” predicting that context will become the fundamental architectural layer in enterprise AI through metadata-driven and AI-augmented solutions. The New Stack has gone further, calling context engineering “the real bottleneck in AI coding” — not compute, not model size, but our ability to capture and convey the implicit knowledge that makes AI systems actually useful.
If you have an enterprise RAG system in production, this matters to you. The question is no longer whether your architecture is working. The question is whether it’s built on a foundation that’s about to become obsolete.
The Death Narrative That Misses the Point
Let’s address the elephant in the room: the “RAG is dead” debate that has consumed technical discourse for the past quarter. VentureBeat declared that “RAG is dead, what’s old is new again.” The New Stack countered that “RAG isn’t dead, but context engineering is the new hotness.” UC Strategies went further, arguing that “Standard RAG Is Dead: Why AI Architecture Split in 2026.”
Here’s what both sides get wrong: they’re treating this as a binary question. RAG isn’t dead. It’s being subsumed. The architecture that emerged as a solution to the “how do we give AI our data” problem is evolving into something broader, more sophisticated, and far more capable. That something is context engineering.
Context engineering represents a fundamental shift in how we think about AI systems and their relationship to information. Traditional RAG treats retrieval as a lookup problem: given a query, find the most relevant documents. Context engineering treats retrieval as a reasoning problem: given a query, understand what information would enable the best possible response, then construct that context dynamically.
The difference is subtle in description but enormous in practice. A traditional RAG system retrieves chunks based on semantic similarity. A context-engineered system might decide that rather than retrieving documents, it needs to execute a sub-query, consult a knowledge graph, pull live data from an API, or synthesize information from multiple sources at once. The retrieval step is still there, but it’s now part of a larger orchestration rather than the entire solution.
The Instructed Retriever Revolution
Databricks has been vocal about this shift, positioning their Instructed Retriever as superior to traditional RAG for enterprise workloads. The key difference, as they’ve articulated it, isn’t about better embedding models or faster vector search. It’s about replacing the passive retrieval component with an active one that can follow instructions about what to retrieve, how to retrieve it, and how to synthesize the results.
Think about what’s happening in a typical enterprise RAG query. A user asks a complex question about company policy. The system embeds the query, searches for similar vectors, returns the top-k chunks, and presents them to the language model. The language model then does its best to construct an answer from potentially fragmented, out-of-context information.
An Instructed Retriever approach flips this process. Instead of passive similarity search, the system receives instructions about the user’s intent, the type of information needed, and the synthesis required. It might break the query into sub-queries, consult different data sources based on the nature of the question, and apply domain-specific reasoning about which information is actually relevant.
This matters because enterprise queries are rarely simple. A question about quarterly revenue might require pulling from financial databases, comparing against historical trends, consulting narrative reports, and factoring in currency adjustments. A traditional RAG system treats this as a single similarity search. A context-engineered system treats it as the complex reasoning task it actually is.
Agentic RAG and the Orchestration Shift
If Instructed Retrievers represent one dimension of this shift, agentic RAG represents another. The rise of multi-agent orchestration in AI systems has been flagged as a breakthrough capability for 2026, with Forbes highlighting it as one of the key trends shaping enterprise AI.
Agentic RAG moves beyond single-step retrieval into multi-step reasoning and action. An agentic system doesn’t just retrieve information. It can decide to retrieve information, evaluate whether that information is sufficient, identify gaps, pull additional context, synthesize findings, and present results. The agent can loop, branch, and adapt its strategy based on what it finds along the way.
This capability changes the game for enterprise use cases. Consider a compliance query that might previously have required a team of analysts working over several days. An agentic RAG system can break down the question, retrieve relevant regulatory documents, apply jurisdiction-specific rules, check against internal policies, flag potential conflicts, and generate a preliminary assessment — all within seconds.
The cost implications are real. Enterprise RAG implementations currently range from $75,000 to $200,000 according to industry benchmarks. Agentic systems cost more to build upfront, but they deliver significantly more value by automating complex workflows that previously required human judgment at every step.
The Enterprise Cost Reality
Let’s be direct about what enterprises are actually spending on AI retrieval systems and what they’re getting for it.
Menlo Ventures and Gartner project enterprise generative AI spending will grow from $37 billion in 2025 to $297 billion by 2027. That’s an extraordinary investment, driven by the realization that AI systems need access to enterprise-specific information to deliver value. But here’s the uncomfortable truth: a significant portion of that spending is going toward systems that aren’t fit for purpose.
Industry estimates suggest around 80% of enterprise RAG projects fail to reach production, or fail once they get there. The reasons are consistent: poor data quality, inadequate retrieval relevance, lack of proper evaluation frameworks, and architectures that can’t handle the complexity of real enterprise queries. Context engineering addresses several of these failure modes by treating retrieval as a first-class engineering challenge rather than a simple embedding problem.
The shift to context engineering isn’t just about better technology. It’s about recognizing that enterprise AI needs a different foundational approach, one that treats context as a dynamic, constructed element rather than a static retrieval output. That requires investment in metadata management, knowledge graph construction, and evaluation frameworks that can assess not just retrieval accuracy but retrieval utility.
Building for the Context Engineering Era
If you’re responsible for an enterprise RAG system, you’re probably wondering what this means for your current infrastructure. The honest answer: it depends. If you have a simple Q&A system over a modest document corpus, traditional RAG might continue to work adequately for years. The context engineering shift matters most for complex enterprise workloads where the limitations of current approaches are already showing.
But if you’re building for the future, the architectural decisions you make now will determine whether you’re positioned to take advantage of these advances. Here are the key considerations.
First, think of retrieval as an orchestration challenge rather than a search challenge. Your system should be capable of deciding what to retrieve, how to retrieve it, and how to synthesize results, not just executing a single similarity search.
Second, invest in your metadata and knowledge graph infrastructure. Context engineering depends on rich metadata that enables reasoning about what information is relevant, not just what is similar.
Third, build evaluation frameworks that measure retrieval utility, not just retrieval accuracy. A system that retrieves technically relevant documents that don’t actually help answer the user’s question is failing, even if its embedding similarity scores look great.
Fourth, think about how your system will evolve to support agentic workflows. The ability to execute multi-step reasoning, loop based on intermediate results, and coordinate across multiple data sources will become table stakes for enterprise AI.
The transition from RAG to context engineering isn’t a disruption. It’s an evolution. Companies that recognize this shift early and build for it will be the ones that extract real value from the $297 billion enterprise AI spending wave. Those that stick with first-generation RAG architectures will find themselves increasingly limited by systems that can’t handle the complexity of real enterprise workloads.
Gartner’s prediction that 2026 would be “the year of context” is proving accurate. The question for enterprise AI leaders isn’t whether to make the transition. It’s whether you’ll lead it or be forced to catch up later, at significantly greater cost.
Your enterprise data holds enormous value. The architecture you choose to access that data determines whether you actually realize it. If you’re ready to assess where your current RAG setup stands and what a context-engineered approach could look like for your organization, that’s the right conversation to start now.


