
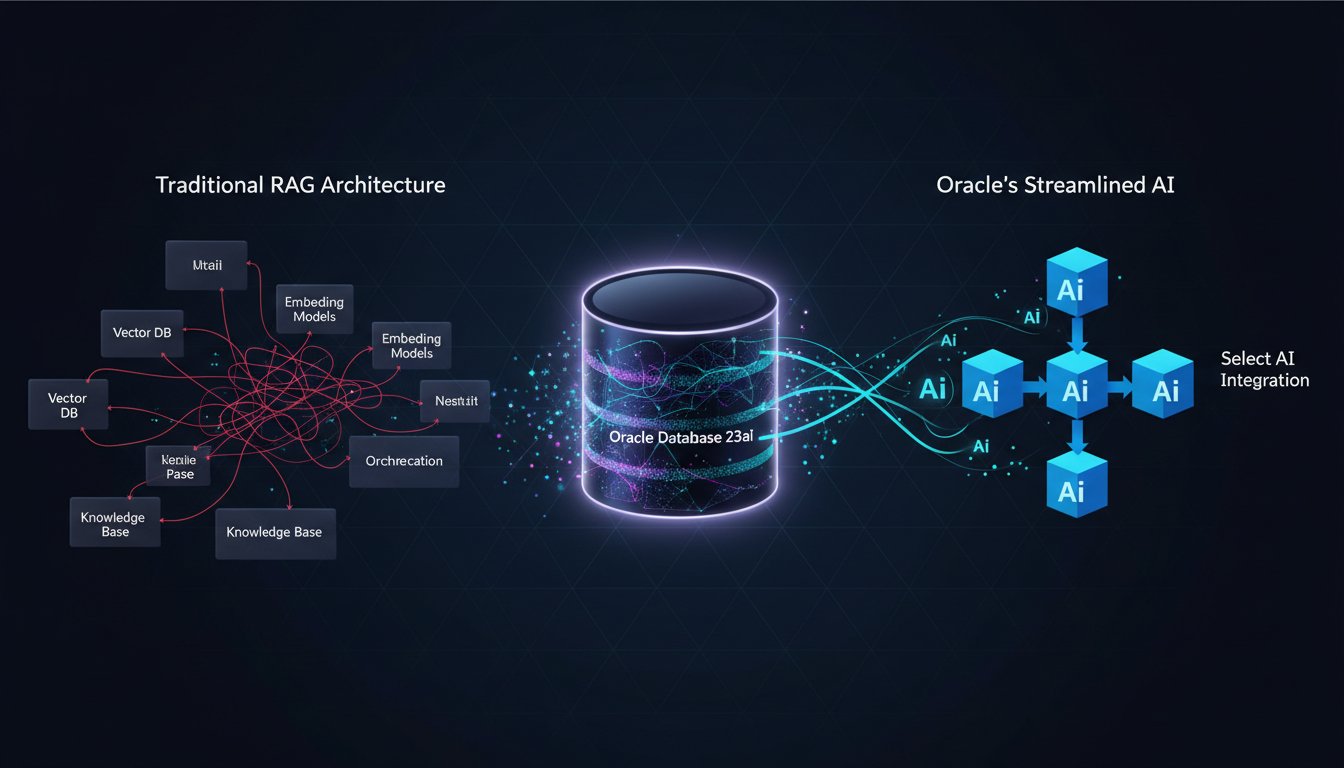
There’s a quiet revolution happening in enterprise RAG deployment, and it’s not coming from the usual suspects. While teams scramble to stitch together vector databases, embedding models, and orchestration frameworks into fragile pipelines, Oracle just flipped the entire architecture on its head. Their Database 23ai and 26ai with Select AI integration proves something controversial: maybe the problem with enterprise RAG isn’t that we need better retrieval systems—it’s that we’ve been building RAG in the wrong place entirely.
For the past two years, the standard enterprise RAG playbook has looked remarkably similar across organizations. Teams deploy a dedicated vector database (Pinecone, Weaviate, Chroma), build a retrieval pipeline using LangChain or Haystack, connect it to their LLM provider, and pray the infrastructure holds together in production. The architecture diagram looks impressive in stakeholder presentations, but in reality, you’re managing data synchronization across multiple systems, dealing with consistency issues between your source database and vector store, and watching latency compound with every network hop.
Oracle’s approach with Select AI and RAG integration in Database 23ai/26ai fundamentally challenges this fragmented architecture. Instead of treating RAG as an external system that periodically syncs with your operational database, they’ve embedded vector search, semantic retrieval, and LLM integration directly into the database layer itself. This isn’t just a feature addition—it’s a complete reconceptualization of where RAG intelligence should live in the enterprise stack.
The implications are profound, and they expose uncomfortable truths about how we’ve been approaching production RAG systems.
The Hidden Cost of Architectural Fragmentation
When you build RAG systems using the conventional multi-component approach, you’re not just adding complexity—you’re introducing failure points that compound exponentially. Every component in your pipeline represents another potential source of latency, inconsistency, and operational overhead.
Consider the typical data flow in a traditional RAG architecture. Your source data lives in an operational database—likely PostgreSQL, MySQL, or yes, Oracle. When documents change, you need an extraction process to identify updates, a transformation pipeline to chunk and embed the content, and a synchronization mechanism to update your vector database. Each of these steps introduces lag. By the time your RAG system retrieves information, it might already be stale.
Now consider Oracle’s integrated approach. Your operational data and your vector embeddings live in the same transactional space. When a record updates in your database, the vector representation can update atomically within the same transaction. There’s no synchronization lag, no eventual consistency concerns, no separate systems to monitor and maintain.
This architectural difference matters enormously for enterprises dealing with rapidly changing data. Financial services firms analyzing real-time market data, healthcare organizations accessing updated patient records, or manufacturing companies tracking inventory movements can’t afford retrieval systems that operate on stale snapshots. The database-integrated approach eliminates an entire class of consistency problems that plague traditional RAG deployments.
Structured and Unstructured Data: The Duality Problem
One of the most frustrating challenges in enterprise RAG is the artificial separation between structured and unstructured data. Your customer information lives in relational tables. Your product documentation exists as unstructured text. Your support tickets contain a mix of both. Traditional RAG systems force you to choose: either focus on semantic search over unstructured content, or query structured data with SQL.
Oracle Database 23ai dissolves this false dichotomy by treating both data types as first-class citizens within the same query paradigm. You can execute a single SQL query that combines traditional relational operations on structured data with semantic vector search on unstructured content. This isn’t just convenient—it fundamentally changes what kinds of questions your RAG system can answer.
Imagine a customer service RAG application that needs to answer: “Show me all high-value customers in the Northeast region who have submitted support tickets about integration issues in the last 30 days, and retrieve the most relevant documentation to resolve their specific problems.” With a fragmented architecture, you’re executing multiple queries across different systems and joining the results in application code. With Oracle’s integrated approach, it’s a single database query that combines structured filters with semantic retrieval.
The technical implementation relies on Oracle’s AI Vector Search capabilities, which enable semantic similarity searches directly within SQL. You can store vector embeddings alongside traditional columns, create vector indexes for performance, and combine vector similarity functions with standard SQL operations. The database handles the complexity of optimizing queries that span both structured predicates and unstructured semantic search.
The Select AI Integration: LLMs Meet Database Transactions
Perhaps the most significant innovation in Oracle’s approach is Select AI with RAG support. This feature brings LLM interaction directly into the database layer, allowing you to augment language model queries with database content using native SQL syntax.
Traditional RAG workflows require orchestration code that runs outside the database. Your application retrieves relevant documents from the vector store, constructs a prompt with the retrieved context, sends it to your LLM API, and processes the response. Each step crosses a network boundary, and the entire workflow exists in stateless application code that has no transactional guarantees.
Select AI flips this model by making LLM augmentation a database operation. You can write SQL queries that invoke language models with context retrieved from the same database, all within a transactional boundary. This means you can combine data retrieval, RAG augmentation, and result persistence in a single database transaction with full ACID guarantees.
The implications for data governance and compliance are substantial. When your RAG operations happen inside the database, you can apply the same security controls, audit logging, and access policies that govern your structured data. There’s no separate vector database with different permission models, no external API calls that bypass your security perimeter, no application-layer code that might inadvertently leak sensitive context to LLM providers.
Implementation Patterns: What Database-Integrated RAG Actually Looks Like
The theoretical advantages of integrated RAG are compelling, but what does implementation actually look like? Oracle’s approach introduces several patterns that differ significantly from conventional RAG development.
First, data preparation moves from external ETL pipelines into database-native operations. Instead of maintaining separate processes to extract, chunk, and embed documents, you can use database triggers and procedures to automatically generate and update vector embeddings when source data changes. This ensures your retrieval index stays synchronized with your operational data without external orchestration.
Second, retrieval queries become standard SQL rather than API calls to specialized vector databases. Developers who already know SQL can write semantic search queries without learning new query languages or SDKs. This dramatically reduces the learning curve for teams implementing RAG systems and allows you to leverage existing database optimization expertise.
Third, monitoring and observability leverage existing database tooling. Oracle provides SQL Performance Watch and other native observability features that work with vector queries just like traditional SQL. You’re not cobbling together monitoring for multiple disparate systems—you’re using proven database performance tools to understand RAG behavior.
The implementation pattern also changes how you think about scaling. Traditional RAG architectures scale horizontally by adding more vector database nodes, more embedding service instances, and more LLM API quota. Oracle’s approach scales vertically within the database infrastructure you’re already managing, leveraging the same clustering, partitioning, and replication strategies that handle your structured data.
The Competitive Landscape: How This Challenges the RAG Tooling Ecosystem
Oracle’s integrated approach represents a direct challenge to the entire ecosystem of specialized RAG tooling that has emerged over the past two years. Companies like Pinecone and Weaviate have built businesses around dedicated vector databases. Frameworks like LangChain and Haystack have standardized on architectures that assume RAG components are separate, specialized systems.
The database-integrated model suggests that for many enterprise use cases, this specialization creates unnecessary complexity. If your source data already lives in a database capable of vector operations and LLM integration, why introduce additional systems that duplicate functionality and create synchronization challenges?
This doesn’t mean dedicated vector databases are obsolete. For AI-first applications where vector embeddings are the primary data model and structured relational data is secondary, specialized vector stores still make sense. But for the vast majority of enterprises whose operational data lives in traditional databases, the integrated approach offers compelling advantages in simplicity, consistency, and operational overhead.
The competitive differentiation also extends to cloud database offerings. While AWS, Google Cloud, and Azure all offer vector database services and RAG tooling, Oracle’s tight integration between vector capabilities, LLM access, and transactional database features creates a cohesive experience that’s difficult to replicate with loosely coupled cloud services.
Real-World Performance: What the Architecture Enables
The architectural differences translate into measurable performance advantages in specific scenarios. Database-integrated RAG particularly excels in situations requiring:
Low-latency retrieval with transactional consistency: When your RAG system needs to reflect data changes immediately and guarantee consistency between structured queries and semantic search, eliminating synchronization lag between separate systems becomes critical.
Complex queries combining structured filters and semantic search: Applications that need to narrow semantic search scope based on structured predicates (time ranges, user permissions, categorical filters) benefit enormously from executing these operations in a single query optimizer rather than joining results across systems.
High-security environments with strict data governance: Industries like healthcare, finance, and government that require comprehensive audit trails and fine-grained access control can leverage database-native security features rather than building equivalent controls across multiple systems.
Operational simplicity for teams without specialized ML infrastructure: Organizations that already have database expertise but limited experience operating specialized vector databases and orchestration frameworks can implement RAG using familiar SQL-based patterns.
The performance profile differs from dedicated vector databases in important ways. Purpose-built vector stores may offer raw vector search speed advantages at massive scale, but database-integrated approaches eliminate the overhead of data transfer, transformation, and synchronization between systems. For enterprise workloads where query complexity and data consistency matter more than pure vector similarity throughput, the integrated model often delivers better end-to-end performance.
The Implementation Reality Check
While Oracle’s approach offers compelling architectural advantages, it’s not a universal solution for every RAG scenario. The integrated model works best when your operational data already lives in Oracle Database, you’re building applications that require tight coupling between structured and unstructured data, and your team has SQL expertise.
If you’re building AI-first applications where vector embeddings are the primary data model, or if your infrastructure is already standardized on cloud-native services from AWS or Azure, migrating to Oracle Database purely for RAG capabilities may not make sense. The architectural benefits have to outweigh the operational complexity of introducing a new database platform.
The model also assumes you’re comfortable with database-centric application architecture. Modern development practices often favor stateless application services with databases as simple persistence layers. Oracle’s RAG integration pushes more intelligence into the database layer, which conflicts with patterns that minimize database logic in favor of application-layer processing.
For organizations already running Oracle Database for operational workloads, however, the integration story is powerful. You’re not introducing new infrastructure—you’re enabling new capabilities in systems you already operate. The incremental complexity is minimal, and you leverage existing database administration expertise rather than building new skillsets around specialized RAG infrastructure.
What This Means for Enterprise RAG Strategy in 2026
Oracle’s database-integrated RAG approach forces a strategic question that enterprise teams need to answer: should RAG be a specialized system you integrate with your database, or a native database capability?
For the past two years, the industry consensus has leaned toward specialized systems. The explosion of vector database startups, the popularity of orchestration frameworks, and the cloud providers’ focus on standalone AI services all reflect an assumption that RAG requires dedicated infrastructure separate from operational databases.
Oracle’s approach suggests this consensus may be wrong for a significant class of enterprise use cases. When your challenge is augmenting existing business applications with AI capabilities—customer service systems that need semantic search over product documentation, financial analysis tools that combine market data with research reports, healthcare applications that retrieve relevant patient history—database integration offers advantages that specialized systems struggle to match.
The strategic implication is that enterprise RAG architecture should start with a fundamental question: where does your source data live, and how does it change? If the answer is “in a relational database with frequent updates requiring transactional consistency,” the database-integrated model deserves serious consideration. If the answer is “in object storage, data lakes, or AI-first vector stores,” specialized RAG infrastructure makes more sense.
This isn’t about Oracle versus competitors—it’s about recognizing that different architectural patterns suit different enterprise needs. The industry’s rush to build specialized RAG infrastructure may have overlooked the advantages of integration with systems that already manage enterprise data.
The Future of Database-Integrated AI
Oracle’s Select AI and vector search integration in Database 23ai/26ai represents more than a product release—it signals a broader pattern of AI capabilities moving into traditional data infrastructure. As language models become essential business tools rather than experimental technologies, the question of where AI processing happens becomes crucial.
The specialized-system model works well for innovation and experimentation. When you’re exploring new AI capabilities, you want flexibility to swap components, try different approaches, and iterate quickly without impacting production systems. But as AI transitions from experimental to operational, the advantages of integration become more important. You want consistency, reliability, and operational simplicity—the same qualities that make databases the foundation of enterprise applications.
We’re likely to see this pattern replicate across the database industry. PostgreSQL extensions like pgvector already bring vector capabilities into open-source databases. MongoDB and other NoSQL platforms are adding semantic search features. The specialized vector database market will continue to serve AI-first use cases, but for traditional enterprises, database-integrated AI may become the default pattern.
Oracle’s approach proves that enterprise RAG doesn’t require abandoning the database infrastructure you already trust and operate. It challenges the assumption that production AI means building complex, fragmented architectures with multiple specialized systems. And it demonstrates that sometimes the most innovative approach isn’t adding new components—it’s integrating intelligence into the systems that already manage your most critical data.
For enterprise teams planning RAG deployments in 2026, the lesson is clear: before you commit to yet another specialized AI infrastructure component, ask whether your existing database can deliver the capabilities you need. The answer might surprise you, and the architectural simplicity might just save your production deployment from becoming another statistic in the 80% failure rate.
The database-integrated RAG revolution isn’t coming from AI startups—it’s coming from the infrastructure that’s been managing enterprise data for decades. And that might be exactly what production AI systems need.


