
Enterprise AI is evolving beyond text-only interactions. While traditional RAG systems excel at retrieving and generating text-based responses, today’s organizations need AI that can understand and work with multiple data types simultaneously. Multi-modal RAG systems represent the next frontier in enterprise AI, enabling organizations to leverage their complete data ecosystem—from documents and images to audio recordings and video content.
The challenge is significant: most enterprise data isn’t purely textual. Customer support interactions include screenshots, product documentation contains diagrams, training materials feature video content, and sales presentations combine text with visual elements. Traditional RAG systems, limited to text processing, miss crucial context and fail to provide comprehensive responses.
Multi-modal RAG systems solve this by integrating multiple data types into a unified retrieval and generation pipeline. These systems can simultaneously search through text documents, analyze images, process audio transcripts, and even understand video content to provide richer, more accurate responses. For enterprises, this means AI that truly understands the full context of business operations.
This comprehensive guide will walk you through building production-ready multi-modal RAG systems, from architecture design to implementation best practices. You’ll learn how to handle different data types, optimize retrieval performance, and ensure your system scales with enterprise demands.
Understanding Multi-Modal RAG Architecture
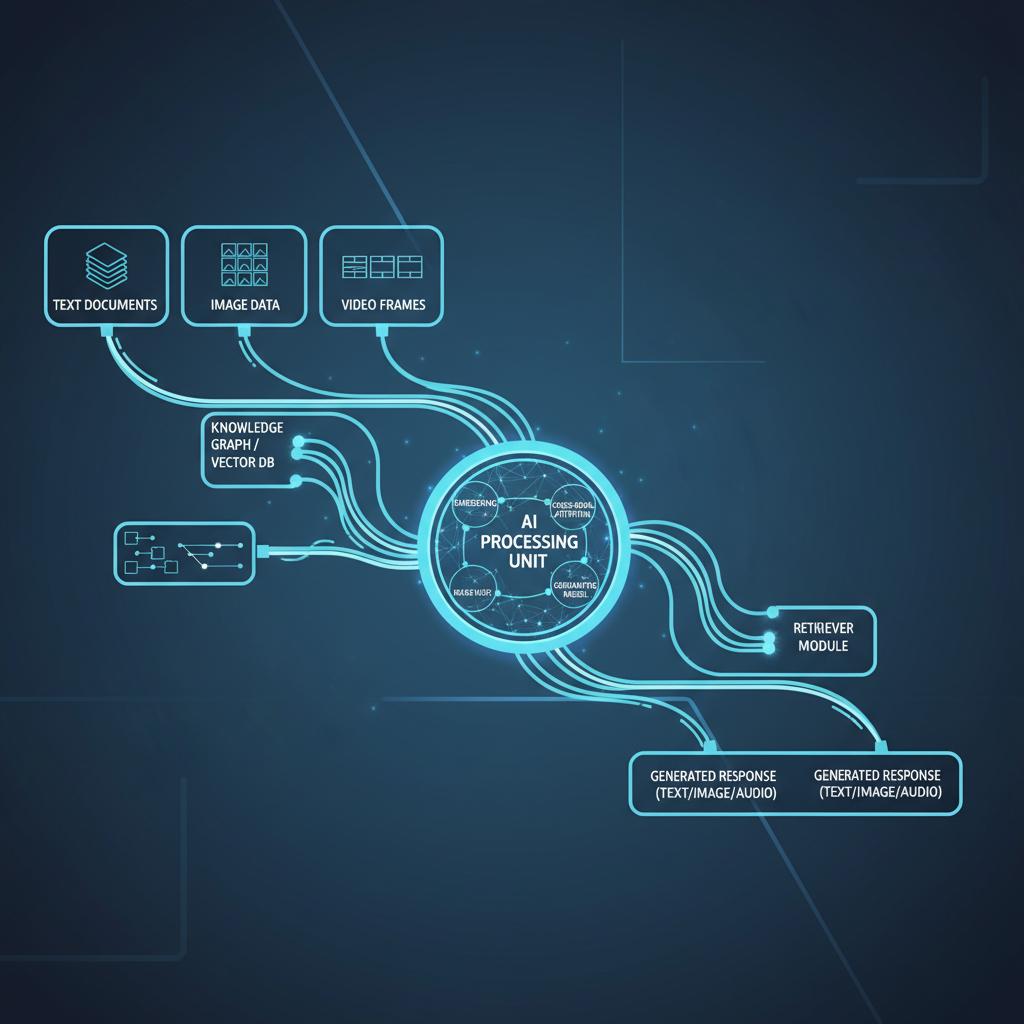
Multi-modal RAG systems extend traditional RAG architecture by incorporating specialized encoders for different data types. Instead of a single text encoder, these systems use multiple encoders—one for text, another for images, and additional encoders for audio and video content.
The core architecture consists of four main components: data ingestion pipelines, modal-specific encoders, unified vector storage, and cross-modal retrieval mechanisms. Data ingestion pipelines handle the preprocessing of different content types, converting images to embeddings, transcribing audio, and extracting text from documents.
Modal-specific encoders are crucial for maintaining data fidelity. Vision transformers like CLIP handle image encoding, while models like Whisper process audio content. Text encoders remain important for document processing, but they now work alongside other specialized models.
Unified vector storage presents unique challenges. Unlike text-only systems that store similar embedding dimensions, multi-modal systems must handle varying vector sizes and types. Modern vector databases like Pinecone, Weaviate, and Qdrant now support multi-modal indexing, allowing you to store and search across different data types efficiently.
Cross-modal retrieval is where multi-modal RAG systems truly shine. These systems can perform semantic searches that span multiple data types—finding relevant images based on text queries, or retrieving documents that relate to visual content. This capability transforms how enterprises access and utilize their data.
Choosing the Right Multi-Modal Models
Model selection significantly impacts system performance and cost. OpenAI’s GPT-4V and Claude 3 offer strong multi-modal capabilities but come with higher costs and API dependencies. Open-source alternatives like LLaVA and InstructBLIP provide more control and lower operational costs.
For image processing, CLIP remains the gold standard for text-image understanding, while models like BLIP-2 excel at image captioning and visual question answering. Audio processing benefits from Whisper for transcription and models like Wav2Vec for audio understanding.
Consider your specific use case when choosing models. Customer support systems might prioritize screenshot analysis, while content management systems need strong document and image correlation capabilities. Financial services might require specialized models for chart and graph interpretation.
Implementing Data Ingestion Pipelines
Effective multi-modal RAG systems require robust data ingestion pipelines that can handle diverse content types while maintaining metadata relationships. Your pipeline must process text documents, extract and analyze images, transcribe audio content, and handle video files.
Document processing extends beyond simple text extraction. Modern pipelines use layout analysis to understand document structure, preserving relationships between text and visual elements. Tools like LayoutLM and DocTR can extract text while maintaining spatial relationships with images and diagrams.
Image processing involves multiple steps: quality assessment, format standardization, and embedding generation. Implement preprocessing that handles different image formats, resizes images for consistent processing, and generates both dense embeddings and descriptive captions.
Audio processing requires transcription, speaker identification, and content segmentation. Whisper provides excellent transcription capabilities, while additional models can identify speakers and segment content by topics. This metadata becomes crucial for retrieval accuracy.
Video processing combines image and audio techniques, adding temporal understanding. Extract keyframes for visual analysis, process audio tracks for transcription, and maintain temporal relationships between visual and audio content.
Handling Metadata and Relationships
Metadata management becomes critical in multi-modal systems. Each data type requires specific metadata: images need resolution and format information, audio files require duration and quality metrics, and documents need structure and formatting details.
Implement relationship tracking between different data types. A product manual might contain text descriptions, technical diagrams, and instructional videos. Your system must understand and maintain these relationships for comprehensive retrieval.
Use hierarchical metadata structures that capture both individual item properties and cross-modal relationships. This enables sophisticated queries that leverage multiple data types simultaneously.
Optimizing Vector Storage and Retrieval
Multi-modal vector storage requires careful consideration of embedding dimensions, storage efficiency, and query performance. Different data types produce embeddings of varying sizes—text embeddings might be 768 dimensions while image embeddings could be 512 or 1024 dimensions.
Implement namespace organization that separates different data types while enabling cross-modal searches. Modern vector databases support metadata filtering that allows you to search within specific data types or across multiple types simultaneously.
Optimize for query patterns common in your organization. If users frequently search for documents related to specific images, implement image-to-text retrieval capabilities. If audio transcripts often reference visual content, build audio-to-image search functionality.
Consider hybrid storage approaches that combine vector databases with traditional databases. Store large media files in object storage while keeping embeddings and metadata in vector databases. This approach optimizes both cost and performance.
Implementing Cross-Modal Search
Cross-modal search enables users to find content across different data types using natural language queries. A user might ask “Show me the installation diagram for the server rack” and receive both the relevant text instructions and associated images.
Implement query understanding that identifies the expected response types. Natural language processing can determine whether users want text, images, or multiple content types. This guides the retrieval strategy and improves response relevance.
Use embedding fusion techniques that combine different modality embeddings for comprehensive similarity scoring. Weight different data types based on query context and user preferences.
Building the Generation Pipeline
The generation pipeline in multi-modal RAG systems must synthesize information from multiple data types into coherent responses. This requires models capable of understanding and referencing different content types within their responses.
Implement context assembly that presents retrieved content in a structured format. Include text snippets, image descriptions, and audio transcripts in a way that large language models can effectively process and reference.
Use prompt engineering techniques that guide models to appropriately reference different content types. Provide clear instructions on how to incorporate visual information, reference audio content, and maintain coherence across multiple data sources.
Consider output format requirements. Some use cases need text-only responses with content references, while others benefit from rich responses that include embedded images or links to audio content.
Handling Model Limitations
Current multi-modal models have limitations in processing multiple content types simultaneously. Implement fallback strategies that ensure system reliability when models encounter unsupported content types or complex multi-modal scenarios.
Use preprocessing to identify content types and route them to appropriate specialized models when general multi-modal models struggle. This hybrid approach maximizes accuracy while maintaining broad capability.
Implement confidence scoring that evaluates the quality of multi-modal responses. Lower confidence scores might trigger human review or alternative processing approaches.
Enterprise-Grade Implementation Considerations
Enterprise deployment requires attention to scalability, security, and integration with existing systems. Multi-modal RAG systems handle larger data volumes and more complex processing than text-only systems, requiring robust infrastructure planning.
Implement horizontal scaling that distributes processing across multiple instances. Different data types may require different computational resources—image processing is GPU-intensive while text processing can run efficiently on CPUs.
Security considerations extend beyond traditional text systems. Image and audio content may contain sensitive information that requires special handling. Implement content filtering and access controls that understand different data types.
Integration with existing enterprise systems requires APIs that can handle multiple content types. Design interfaces that accept various input formats while providing consistent output structures.
Monitoring and Optimization
Multi-modal systems require comprehensive monitoring that tracks performance across different data types. Monitor embedding generation times, retrieval accuracy, and generation quality for each modality separately.
Implement A/B testing frameworks that can evaluate multi-modal responses against text-only baselines. This helps quantify the value of multi-modal capabilities and guide optimization efforts.
Use feedback loops that capture user interactions with different content types. This data guides model fine-tuning and system optimization efforts.
Advanced Features and Future Considerations
Advanced multi-modal RAG systems can implement features like content generation, style transfer, and interactive visual search. These capabilities transform RAG from a retrieval system into a comprehensive content platform.
Content generation features enable systems to create new visual content based on retrieved information. This might include generating diagrams to explain complex concepts or creating visual summaries of text content.
Style transfer capabilities allow systems to adapt visual content to organizational standards. Retrieved images can be automatically styled to match brand guidelines or presentation formats.
Interactive visual search enables users to upload images and find related content across all data types. This powerful capability transforms how users discover and access organizational knowledge.
Preparing for Future Developments
The multi-modal AI landscape evolves rapidly. Design systems with flexible architectures that can incorporate new models and capabilities as they become available. Modular designs enable easy upgrades without system-wide changes.
Consider emerging modalities like 3D content, sensor data, and real-time video streams. While not immediately necessary, architectural decisions should accommodate future expansion into these areas.
Plan for improved model capabilities that might change processing requirements. More efficient models could enable real-time multi-modal processing, while larger models might require additional computational resources.
Multi-modal RAG systems represent a significant advancement in enterprise AI capabilities. By following this implementation guide, you can build systems that truly understand and leverage your organization’s complete data ecosystem. Start with a focused use case, implement robust data pipelines, and scale gradually as you prove value and gain experience. The investment in multi-modal capabilities will pay dividends as your organization’s data complexity continues to grow, positioning you at the forefront of enterprise AI innovation. Ready to transform how your organization accesses and utilizes its multi-modal data? Begin with a pilot project that demonstrates clear business value, then expand systematically across your enterprise.


