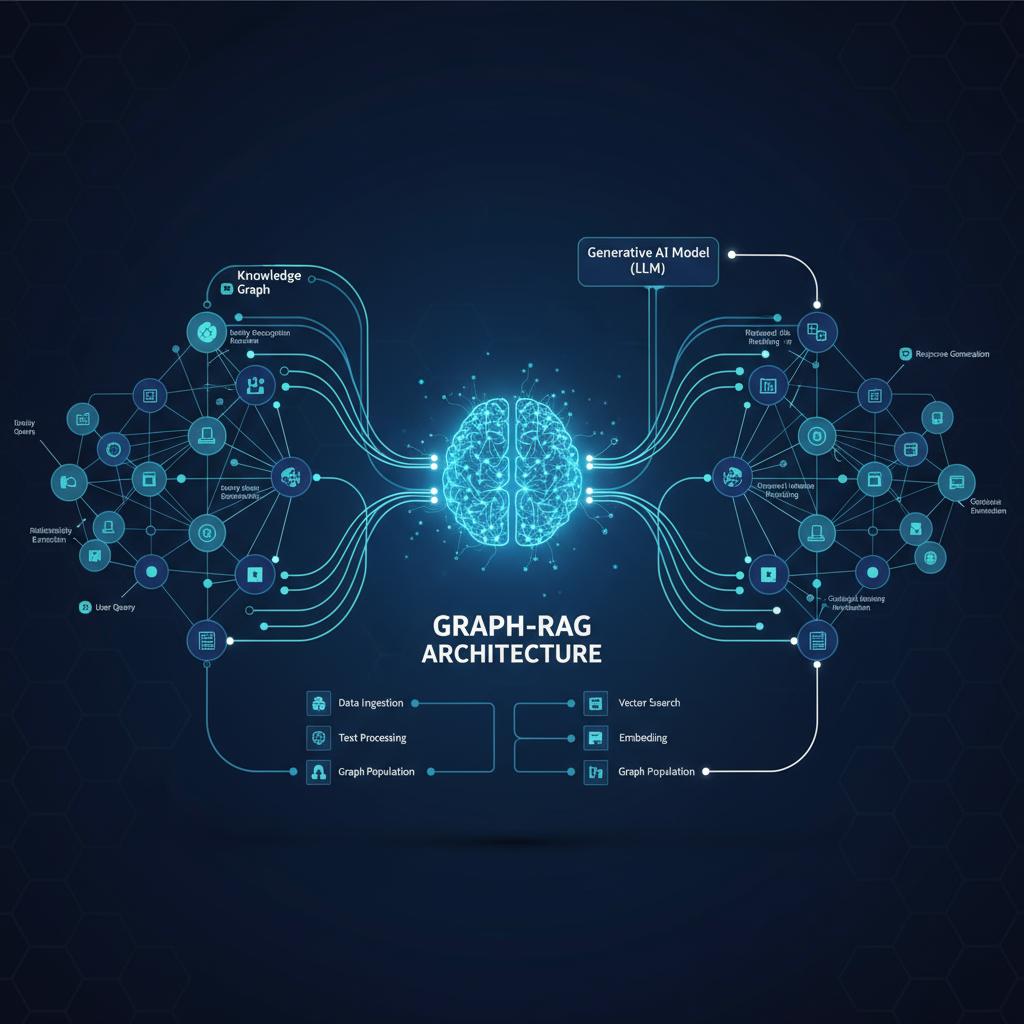
Enterprise AI systems are hitting a wall. Traditional RAG implementations retrieve isolated chunks of information, missing the rich relationships that make data truly intelligent. While your vector databases excel at finding similar content, they fail to understand how different pieces of information connect, relate, and influence each other.
This limitation becomes critical when dealing with complex enterprise scenarios where context isn’t just about content similarity—it’s about understanding relationships, hierarchies, and dependencies. A query about “project risks” shouldn’t just return documents containing those keywords; it should understand how risks relate to timelines, budgets, stakeholders, and mitigation strategies.
GraphRAG represents the next evolution in enterprise AI architecture, combining the relationship modeling power of knowledge graphs with the retrieval capabilities of traditional RAG. This hybrid approach doesn’t just find relevant information—it understands how that information fits into the broader context of your organization’s knowledge ecosystem.
In this comprehensive guide, we’ll walk through building production-ready GraphRAG systems that transform how your enterprise AI understands and retrieves interconnected information. You’ll learn to implement graph-enhanced retrieval that maintains context while scaling to enterprise data volumes.
Understanding GraphRAG Architecture
GraphRAG fundamentally reimagines how we structure and retrieve information by treating data as an interconnected web rather than isolated documents. Traditional RAG systems store content in vector embeddings, losing the semantic relationships between entities, concepts, and documents.
The GraphRAG architecture introduces three core components that work together. The knowledge graph layer stores entities and their relationships, creating a semantic map of your information landscape. The vector retrieval layer maintains the similarity-based search capabilities of traditional RAG. The graph-enhanced retrieval engine orchestrates both systems, using graph traversal to expand and contextualize vector search results.
This architecture addresses critical limitations in enterprise scenarios. When a traditional RAG system searches for information about “Q4 budget planning,” it might return relevant documents but miss the connections to related projects, historical spending patterns, or dependent initiatives. GraphRAG understands these relationships, providing richer, more contextual responses.
The implementation complexity varies based on your data structure and use cases. Simple GraphRAG systems might focus on entity extraction and basic relationships, while advanced implementations can model complex organizational hierarchies, temporal relationships, and multi-dimensional dependencies.
Building the Knowledge Graph Foundation
Successful GraphRAG implementation starts with designing a knowledge graph that accurately represents your domain’s semantic structure. This process begins with entity identification and relationship mapping, followed by graph schema design that balances expressiveness with query performance.
Entity extraction forms the backbone of your knowledge graph. Modern NLP models like spaCy’s entity recognizer or custom fine-tuned transformers can identify people, organizations, locations, and domain-specific entities from your documents. The key is creating consistent entity resolution—ensuring that “John Smith,” “J. Smith,” and “Smith, John” all reference the same entity.
Relationship extraction requires more sophisticated approaches. Rule-based systems work well for structured data and common relationship patterns, while neural models excel at extracting implicit relationships from unstructured text. OpenAI’s GPT models can identify complex relationships when prompted with specific schemas, making them valuable for bootstrapping relationship extraction.
Graph schema design determines how effectively your system can answer complex queries. Start with core entity types relevant to your domain—for enterprise systems, this might include employees, projects, documents, processes, and organizational units. Define relationship types that capture meaningful connections: “works_on,” “reports_to,” “depends_on,” “influences.”
Implement your knowledge graph using production-ready graph databases like Neo4j, Amazon Neptune, or Apache AGE. These systems provide ACID compliance, horizontal scaling, and optimized graph traversal algorithms essential for enterprise deployments.
Implementing Graph-Enhanced Retrieval
Graph-enhanced retrieval orchestrates traditional vector search with graph traversal to provide contextually rich information retrieval. This process involves query analysis, hybrid search execution, and result synthesis that maintains both relevance and relationships.
Query analysis determines the optimal retrieval strategy for each user query. Simple factual queries might rely primarily on vector search, while complex analytical questions benefit from graph traversal. Implement query classification using intent recognition models that route queries to appropriate retrieval pathways.
The hybrid search process begins with vector retrieval to identify initially relevant documents or entities. These results serve as entry points into the knowledge graph, where graph traversal algorithms explore connected information. Implement breadth-first search for immediate relationships or depth-first search for exploring specific relationship chains.
Path-based retrieval adds sophisticated relationship reasoning to your system. When users ask about “project dependencies,” the system can traverse dependency relationships to identify not just direct dependencies but also transitive dependencies that might impact project outcomes.
Result synthesis combines vector search relevance scores with graph-based relationship weights to rank results. Implement scoring algorithms that consider both content similarity and relationship proximity, ensuring that highly connected entities receive appropriate attention in final results.
Optimizing Performance and Scalability
Enterprise GraphRAG systems must handle massive knowledge graphs while maintaining sub-second query response times. Performance optimization requires careful attention to graph indexing, query optimization, and caching strategies.
Graph indexing strategies significantly impact query performance. Create specialized indexes for frequently accessed entity types and relationship patterns. Neo4j’s native indexes excel at exact matches, while full-text indexes support fuzzy entity matching. Implement composite indexes for multi-dimensional queries that filter on multiple entity properties.
Query optimization becomes critical as graph complexity increases. Pre-compute common traversal patterns and store results as materialized views. Implement query plan analysis to identify expensive operations and optimize graph traversal paths. Use graph algorithms like shortest path or community detection to pre-calculate frequently needed relationship information.
Caching strategies must balance memory usage with query performance. Implement multi-level caching that stores frequently accessed entities in memory while maintaining larger relationship patterns in distributed caches. Redis clusters work well for caching graph traversal results, while in-memory caches handle entity lookups.
Horizontal scaling requires careful graph partitioning strategies. Implement domain-based partitioning that keeps related entities on the same graph instances, minimizing cross-partition queries. Use graph replication for read-heavy workloads and implement eventual consistency patterns for distributed graph updates.
Advanced GraphRAG Patterns
Sophisticated GraphRAG implementations leverage advanced graph algorithms and machine learning techniques to provide intelligent relationship discovery and dynamic graph evolution.
Temporal GraphRAG adds time-based reasoning to your knowledge graph, enabling queries about how relationships and entities change over time. Implement temporal edges that track relationship validity periods and entity state changes. This capability proves essential for enterprise scenarios involving project timelines, organizational changes, and regulatory compliance.
Multi-hop reasoning allows your system to answer complex questions requiring multiple relationship traversals. Implement reasoning chains that can connect disparate pieces of information through intermediate relationships. For example, connecting a customer complaint to potential product improvements through relationship chains involving support tickets, product features, and development roadmaps.
Dynamic graph expansion automatically discovers new relationships from incoming data streams. Implement machine learning pipelines that analyze new documents for potential entity relationships, proposing graph updates for human validation. This approach ensures your knowledge graph evolves with your organization’s changing information landscape.
Federated GraphRAG connects multiple knowledge graphs across different domains or organizational units while maintaining data governance boundaries. Implement cross-graph query protocols that can traverse relationships spanning multiple graph instances without compromising security or access controls.
Production Deployment and Monitoring
Deploying GraphRAG systems in production environments requires robust infrastructure, comprehensive monitoring, and effective data governance frameworks.
Infrastructure requirements include high-memory graph database clusters, vector database instances, and orchestration services that coordinate hybrid retrieval operations. Implement containerized deployments using Kubernetes for scalable, resilient system architecture. Plan for data backup and disaster recovery procedures that maintain both graph structure and vector embeddings.
Monitoring GraphRAG systems requires tracking both traditional retrieval metrics and graph-specific performance indicators. Monitor query response times, graph traversal depths, cache hit rates, and relationship accuracy scores. Implement alerting systems that detect graph corruption, unusual query patterns, and performance degradations.
Data governance becomes complex when dealing with interconnected information. Implement access controls that respect both document-level permissions and relationship-based access patterns. Ensure that graph traversal operations don’t inadvertently expose information through relationship chains that bypass intended access restrictions.
Version control for knowledge graphs requires specialized approaches that track both structural changes and content updates. Implement graph versioning systems that can rollback schema changes, track entity evolution, and maintain audit trails for relationship modifications.
GraphRAG represents a fundamental shift in how enterprise AI systems understand and retrieve information. By combining the relationship modeling power of knowledge graphs with the retrieval capabilities of traditional RAG, organizations can build AI systems that truly understand the interconnected nature of enterprise knowledge. The implementation complexity requires careful planning and expertise, but the resulting capabilities transform how teams access and leverage organizational intelligence. Start with focused use cases that demonstrate clear value, then expand your GraphRAG implementation as your team gains experience with graph-enhanced retrieval patterns.