
Category: Technical Deep-Dive
-
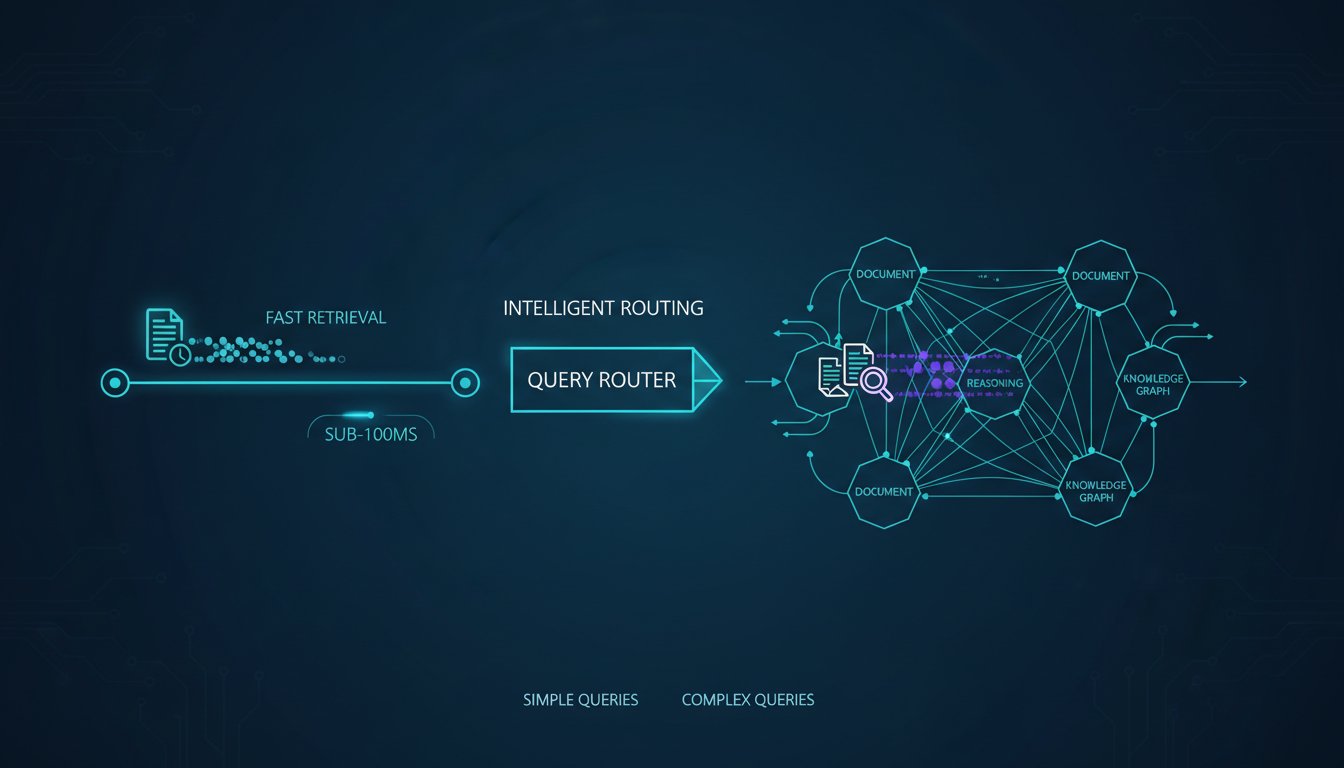
Query-Adaptive RAG: Routing Complex Questions to Multi-Hop Retrieval While Keeping Simple Queries Fast
Imagine your enterprise RAG system answers factual questions perfectly—until users ask something that requires connecting information across multiple documents. Suddenly, your precision drops 40%. Your team blames the vector database. You blame the LLM. Neither is the problem. The real issue? You’re treating every query the same way. A straightforward question like “What’s our Q4…
-
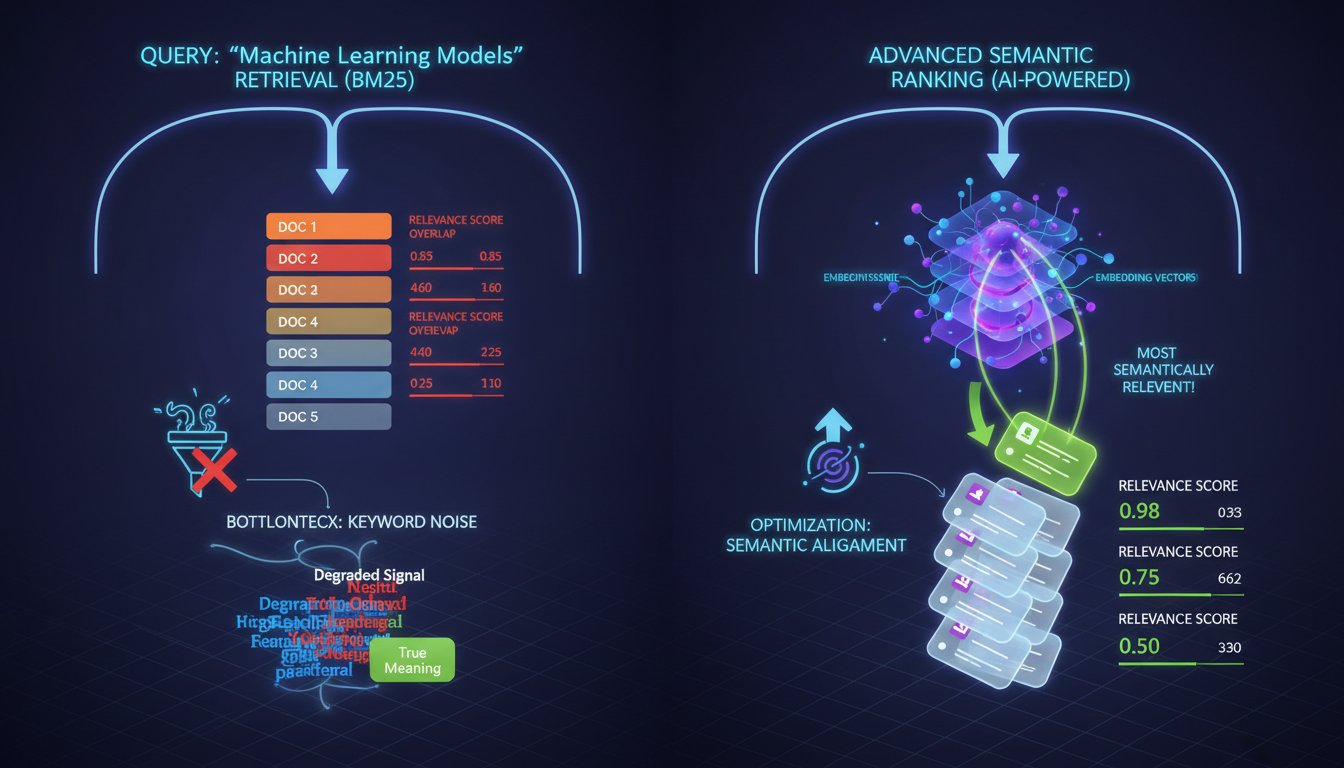
The Retrieval-Ranking Bottleneck: Why Your RAG System Stops Improving After the First 50 Retrieved Documents
Your RAG system retrieves documents in milliseconds. Your LLM generates responses in seconds. But somewhere between those two steps, your accuracy plateaus. This isn’t a retrieval problem. Your embedding model is probably working fine—pulling relevant documents from your knowledge base with reasonable precision. The issue isn’t speed either; your latency metrics look solid. The real…
-

The Context Collapse Crisis: Why Your Multi-Turn RAG System Loses Track After 5 Questions
Every enterprise RAG system starts with promise. Your first query returns perfect results—sources cited, context grounded, hallucinations eliminated. Your second query? Still solid. But by your fifth or sixth turn in a conversation, something insidious happens. The model drifts. It forgets earlier constraints you set. It retrieves documents that seem relevant but contradict information from…
-
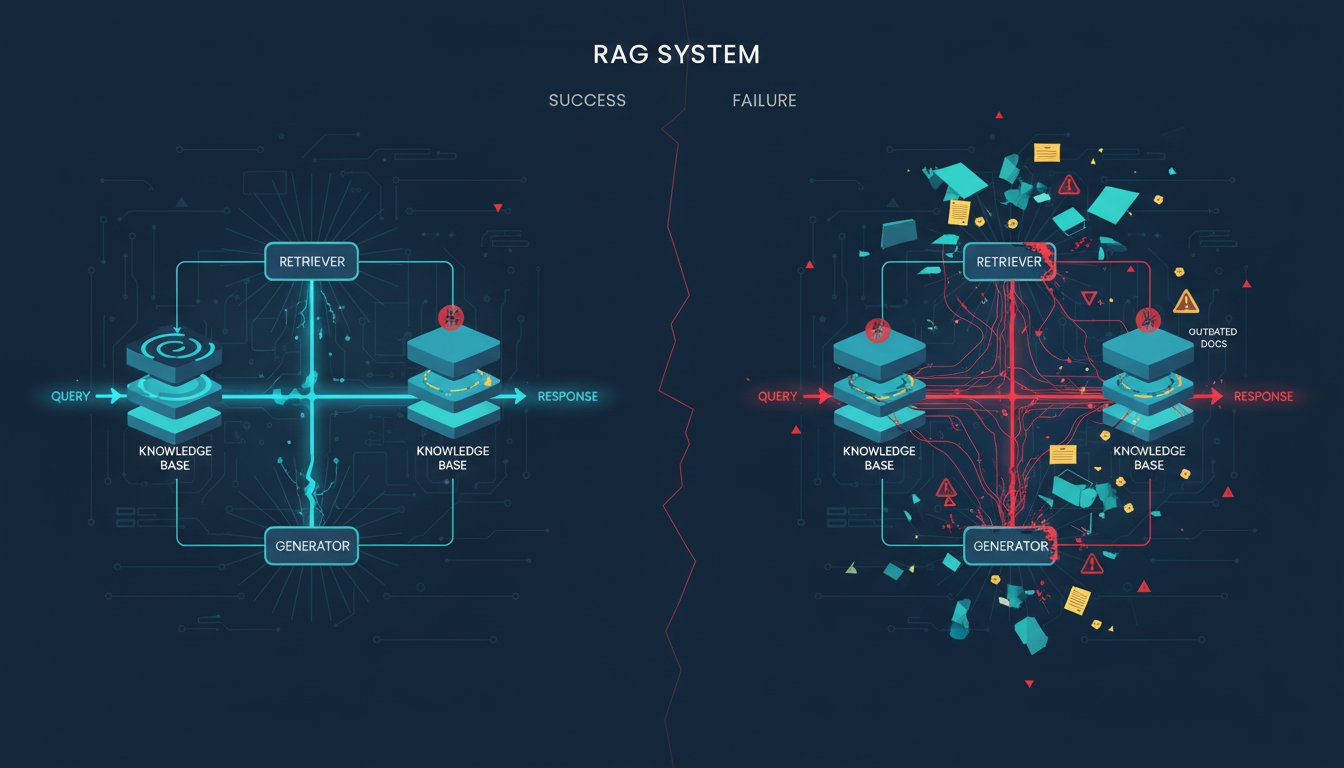
The Engineering Gap: Why 73% of Enterprise RAG Systems Fail Where They Matter Most
The gap between a working RAG prototype and a production system that actually delivers business value is wider than most organizations realize. You can build something that works beautifully in a demo environment—retrieving documents, generating responses, passing internal tests—and still watch it fail spectacularly when enterprises put real data through it at scale. Here’s the…