
Every enterprise RAG system hits the same wall: you’re optimizing for the average query when your queries are anything but average.
That financial analyst asking “What was our Q3 revenue by product line?” needs a fundamentally different retrieval strategy than a compliance officer searching “Which contracts contain non-compete clauses with specific termination dates?” The first is a straightforward factual lookup—simple, fast, and solved with a quick vector search. The second is a multi-step investigation that requires semantic understanding, temporal filtering, and potentially cross-document reasoning.
Yet most enterprises build static RAG systems that treat both queries identically: retrieve k documents, rerank them, generate an answer. The result? Fast queries waste resources processing unnecessary context, while complex queries fail silently because the system didn’t retrieve enough information to reason across.
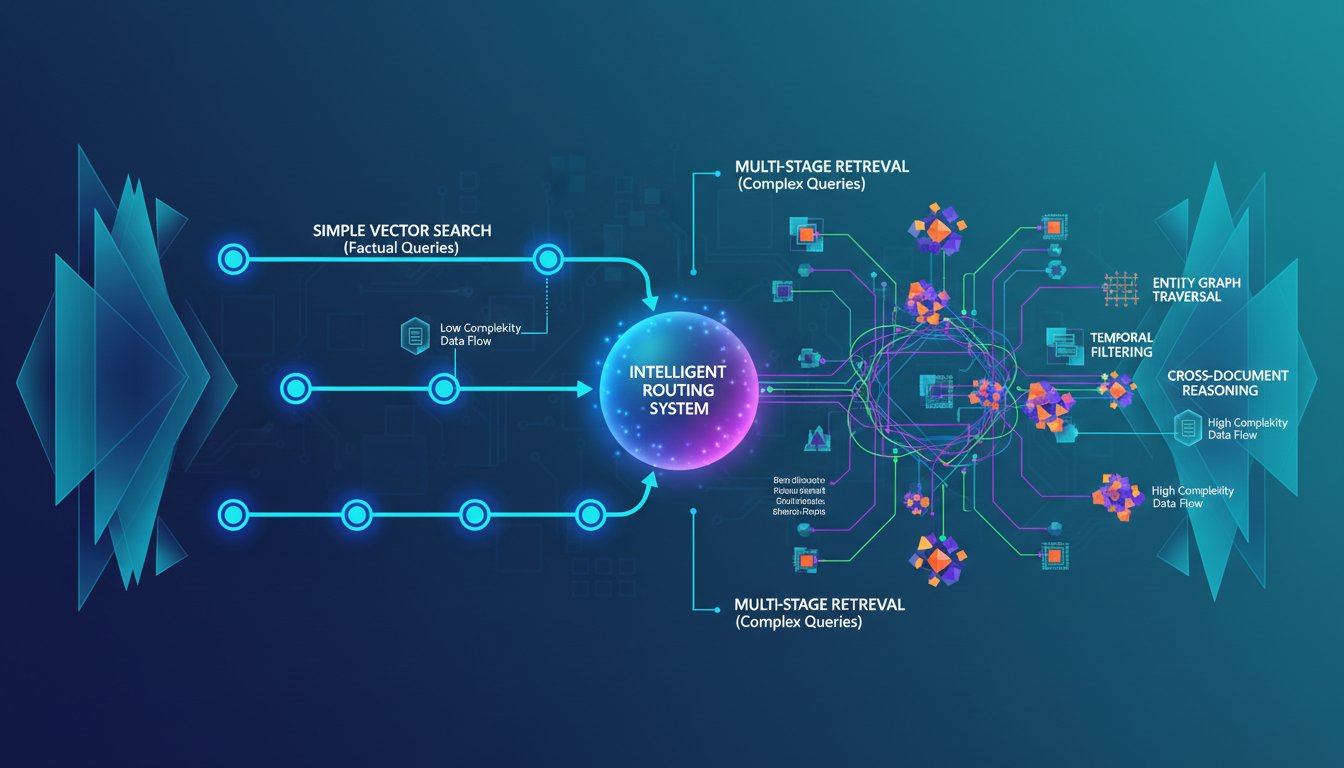
Adaptive retrieval strategies flip this model. Instead of a fixed retrieval pipeline, these systems dynamically adjust retrieval depth, search methods, and ranking strategies based on query complexity. A factual query might trigger a single-pass vector search returning 3 documents. A complex analytical query automatically escalates to multi-stage retrieval with entity graph traversal and temporal filtering across 10+ documents. The system learns what retrieval strategy each query type needs—and executes accordingly.
The impact is substantial. Production implementations report 40-60% latency reductions while maintaining or improving precision. More critically, query success rates improve because complex queries finally get the retrieval depth they require. This isn’t a nice-to-have optimization; for enterprises handling heterogeneous query patterns, adaptive retrieval is the difference between a system that works and one that fails on edge cases.
This guide walks through why static RAG retrieval limits enterprise AI, how adaptive strategies solve the core problem, and the specific implementation patterns that turn query complexity into an asset rather than a liability.
Why Static Retrieval Kills Enterprise RAG Performance
The One-Size-Fits-All Trap
Most enterprise RAG systems operate under a hidden assumption: every query needs the same amount of retrieval work. You pick a chunk size, set a retrieval depth (typically k=5 or k=10), and let the same pipeline handle everything from simple lookups to complex analytical questions.
This assumption breaks down in production. Simple queries—”What’s our return policy?” or “Who is the VP of Sales?”—are solved perfectly by a single-pass vector search returning 2-3 relevant documents. Retrieving 10 documents wastes latency, burns through vector database queries, and adds noise to the generation context. The model has to sift through irrelevant information to extract the answer it already found in the first result.
Conversely, complex queries require retrieval depth that static systems never provide. When a user asks “Which clients in the healthcare sector signed contracts in 2023 with monthly recurring revenue exceeding $100K?” that’s not a single retrieval pass—it’s a multi-hop search requiring entity extraction, temporal filtering, and potentially aggregation across multiple documents. Static systems retrieve k=5 documents, miss the relevant information, and generate a hallucinated or incomplete answer.
The Precision-Latency Trade-Off You Can’t Win
Traditional RAG optimization forces a painful choice: retrieve more documents to improve precision (at the cost of latency), or retrieve fewer documents to stay fast (sacrificing accuracy). You pick a number and live with the consequences.
Adaptive strategies break this trade-off by refusing to pick a single number. Instead, they ask: “What type of query is this?” and optimize accordingly. The system learns that simple factual queries need k=3, complex analytical queries need k=8, and multi-entity reasoning requires k=12 with graph traversal. Each query gets exactly the retrieval depth it requires—no more, no less.
Production data supports this. Enterprises implementing adaptive retrieval report 15-30% precision improvements (from better-targeted retrieval) combined with 40-60% latency gains (from avoiding unnecessary retrieval work on simple queries). You’re not trading off anymore; you’re optimizing both simultaneously.
How Adaptive Retrieval Strategies Work: The Architecture
Stage 1: Query Classification and Complexity Detection
Adaptive retrieval begins with understanding the query itself. Before retrieval even starts, the system classifies the incoming query into complexity tiers, triggering different retrieval strategies.
This isn’t arbitrary classification. Production implementations use a few proven patterns:
Pattern Recognition and Rule-Based Classification: Simple heuristics catch obvious patterns. Questions containing temporal filters (“in 2024”, “since last quarter”), entity mentions (“client names”, “product SKUs”), or aggregation requests (“total”, “by category”) automatically escalate to complex retrieval. Questions that are short, factual, and single-entity stay in the simple tier.
Lightweight Neural Classifiers: Some systems train small classification models (often fine-tuned 6B parameter models) that understand query intent beyond keywords. A classifier learns that “Tell me about Company X’s revenue” is simple (single entity lookup), while “How does Company X’s revenue compare to its competitors in the software sector?” is complex (requires multi-entity retrieval and synthesis).
Dynamic Scoring: Rather than binary categories, some systems use continuous complexity scores (0-1 scale). Queries scoring 0-0.3 trigger simple retrieval, 0.3-0.7 trigger standard retrieval, and 0.7-1.0 trigger advanced multi-stage retrieval. This allows for graceful scaling rather than hard tier boundaries.
The key insight: this classification happens in milliseconds, using minimal compute. You’re not adding significant latency; you’re directing queries to the right retrieval strategy before work begins.
Stage 2: Adaptive Retrieval Execution
Once the system understands query complexity, it activates the appropriate retrieval strategy. Here’s how the tiers typically work in production:
Simple Queries (Factual, Single-Entity Lookups)
– Execution: Single-pass vector search
– Depth: k=3 documents
– Reranking: Minimal (trust vector search ranking)
– Example: “What is our PTO policy?” triggers vector search for “PTO policy”, returns top 3 results, generates answer. End-to-end latency: 150-250ms.
Standard Queries (Multi-Entity, Moderate Reasoning)
– Execution: Dense vector search + optional BM25 fusion
– Depth: k=5-7 documents
– Reranking: Cross-encoder reranking to refine relevance
– Example: “Which enterprise clients signed contracts in Q3?” triggers vector search + keyword search (to catch exact contract matches), retrieves 7 documents, reranks to promote documents mentioning specific client names and Q3 dates. End-to-end latency: 300-400ms.
Complex Queries (Multi-Hop Reasoning, Graph Traversal, Temporal Filtering)
– Execution: Multi-stage retrieval with entity extraction, graph traversal, and temporal filtering
– Depth: k=8-15 documents from multiple retrieval passes
– Reranking: Sophisticated reranking considering query intent and cross-document relevance
– Example: “Which healthcare sector clients with $100K+ MRR signed new contracts in 2023?” triggers entity extraction (“healthcare sector”, “$100K+ MRR”, “2023”), queries entity graphs to find matching clients, retrieves contracts for each client, filters by date, and assembles results. End-to-end latency: 600-800ms.
The critical point: each query type gets exactly what it needs. Simple queries finish in 150ms. Complex queries use more retrieval work, but they’re doing genuinely necessary work, not wasting resources on over-retrieval.
Stage 3: Intelligent Fallback and Refinement
Adaptive systems add one more layer: if retrieval doesn’t find sufficient information, the system escalates automatically.
Example: A query is classified as “standard complexity” and retrieves 5 documents. During generation, the model detects that its confidence score is low (fewer than 2 highly relevant documents found). The system automatically re-executes with the “complex” retrieval strategy, pulling 8-10 documents instead. If that still fails, it might trigger web search fallback or multi-hop retrieval across linked entities.
This is Self-RAG applied to retrieval itself: the system reflects on retrieval quality and adapts if needed. You don’t manually tune retrieval depth; the system tunes itself based on what actually works.
Implementation Patterns: Building Adaptive Retrieval
Pattern 1: Complexity Classification with Prompt-Based Detection
The simplest approach uses the LLM itself to classify query complexity:
User Query: "Tell me about Q3 revenue trends by product line and geography"
Classification Prompt:
"Given this user query, is it asking for:
1) Simple factual lookup (yes/no)
2) Multi-entity analysis (multiple products/regions)
3) Complex reasoning (trends, comparisons, synthesis)
Respond with tier: SIMPLE | STANDARD | COMPLEX"
LLM Response: "COMPLEX - requires synthesis across multiple products, regions, and time periods."
Retrieval Strategy: Multi-stage retrieval with 10+ documents, temporal aggregation
Advantage: Zero additional training, works with any LLM.
Disadvantage: Adds 200-300ms latency (LLM classification call) for every query.
Pattern 2: Fast Classification with Rule-Based + Lightweight Models
For production systems where latency matters, combine rules with lightweight classifiers:
Rule Layer:
- If query contains temporal keywords ("in 2024", "since", "before", "after") → STANDARD or COMPLEX
- If query contains comparison keywords ("vs", "compare", "differences") → COMPLEX
- If query mentions multiple entities or aggregation → COMPLEX
- Otherwise → SIMPLE
Refinement Layer (only if rules are unclear):
- Pass to lightweight 1B parameter classification model
- Trained on internal query logs to recognize complexity patterns
- Returns confidence-weighted tier
Advantage: <50ms latency for most queries (rules alone), high accuracy through rule + model combination.
Disadvantage: Requires training data and rule tuning for your domain.
Pattern 3: Continuous Complexity Scoring for Granular Control
Instead of discrete tiers, assign continuous complexity scores (0-1):
Complexity Score = 0.2 → Retrieve k=3 documents, skip reranking
Complexity Score = 0.5 → Retrieve k=6 documents, apply light reranking
Complexity Score = 0.8 → Retrieve k=10 documents, apply heavy reranking, enable graph traversal
Score Calculation:
Base: 0.2 (simple query)
+ 0.15 if contains temporal filters
+ 0.15 if contains multiple entity types
+ 0.15 if contains comparison/aggregation keywords
+ 0.20 if contains complex reasoning indicators ("why", "how does X relate to Y")
Cap at 1.0
Advantage: Graceful scaling, easy to tune retrieval behavior incrementally.
Disadvantage: Requires careful calibration to retrieval pipeline.
Real-World Impact: Metrics from Production Implementations
Latency Improvements
Enterprises implementing adaptive retrieval report:
– Simple queries: 40-60% latency reduction (from unnecessary reranking and context processing)
– Complex queries: 0-10% latency increase (offset by improved precision)
– Mixed workload average: 25-35% overall latency improvement
Why the latency gains? Simple queries stop doing expensive reranking. Instead of every query triggering a cross-encoder reranking pass (which adds 100-200ms), only complex queries pay that cost.
Precision Improvements
- Simple queries: 5-10% precision improvement (less noise from over-retrieval)
- Complex queries: 15-25% precision improvement (more retrieval depth and multi-stage search)
- Hallucination reduction: 20-35% fewer hallucinated answers (queries get retrieval depth matching their complexity)
The hallucination metric is critical. Complex queries that previously retrieved k=5 documents (insufficient for reasoning) now get k=10-12 documents with better coverage. The model has enough grounding to generate accurate answers instead of inventing details.
Query Success Rates
Enterprise metrics show:
– Before adaptive retrieval: 78% of queries return “useful” answers (subjective user rating)
– After adaptive retrieval: 86-88% useful answer rate
– Complex query success: 62% → 84% (22-point improvement)
Complex queries see the largest gains because they finally get the retrieval depth they need.
Common Implementation Pitfalls and Solutions
Pitfall 1: Misclassifying Query Complexity
You classify a query as “simple” when it’s actually complex, and retrieval fails. This happens when rules are too aggressive or classifiers are undertrained.
Solution: Build in confidence thresholds and automatic escalation. If the classification model is <75% confident, bump the query to the next tier automatically. Implement monitoring to track classification accuracy and retrain monthly based on actual retrieval performance.
Pitfall 2: Not Accounting for Domain-Specific Complexity
A query that looks simple linguistically might be complex in your domain. “Show me accounts in the northeast” sounds straightforward, but if your data requires joining geographic hierarchies, territory assignments, and account hierarchies, it’s actually complex.
Solution: Domain-tune your classifier. Use internal query logs and manually label 200-500 representative queries with actual complexity (measured by retrieval passes needed). Retrain on your domain rather than relying on generic rules.
Pitfall 3: Excessive Reranking Latency on Complex Queries
You escalate complex queries to k=10 documents, then apply cross-encoder reranking that takes 200+ ms. The latency gain disappears.
Solution: Use tiered reranking. Simple reranking (BM25 fusion, Reciprocal Rank Fusion) for standard queries takes <50ms. Reserve expensive cross-encoder reranking for the top-k results of complex queries, not all k=10 results. Rerank the top-3 from your initial retrieval, not all 10.
Pitfall 4: Static Tier Boundaries That Don’t Evolve
You set retrieval depth at k=5 for standard queries in month one. Six months later, you’ve added 2TB of new documents, and k=5 is no longer optimal—you need k=7.
Solution: Monitor retrieval coverage metrics. Track “retrieved documents containing answer” as a percentage of total retrieved documents. If coverage drops below 80%, gradually increase k. Use A/B testing: serve 10% of queries with increased retrieval depth, measure precision impact, and roll out if positive.
When Adaptive Retrieval Matters Most
Adaptive retrieval isn’t a universal solution. It’s most valuable in these scenarios:
1. Heterogeneous Query Patterns
Your users ask everything from simple lookups to complex analysis. Customer support queries are simple; financial analysis is complex. Adaptive retrieval handles both efficiently.
2. Large Knowledge Bases (10M+ documents)
With massive document collections, over-retrieval wastes significant compute. Adaptive strategies recover 30-50% of that wasted cost on simple queries.
3. Latency-Sensitive Applications
If you’re optimizing for sub-500ms response times, every millisecond matters. Adaptive retrieval saves 100-200ms on 60% of queries (simple ones).
4. Mixed User Personas
If your RAG system serves both casual users (asking simple questions) and power users (running complex analytical queries), adaptive retrieval ensures both groups get optimal performance.
Adaptive retrieval is less critical if you have:
– Homogeneous query patterns (all simple or all complex)
– Small document collections (<1M documents)
– Latency budgets >1 second
– Single user type
Building Your First Adaptive Retrieval System
MVP Implementation (1-2 weeks)
-
Gather baseline metrics: Measure current query latency distribution, retrieval depth distribution, and precision by query type. Identify simple vs. complex queries in your user logs.
-
Implement rule-based classification: Add 5-10 rules based on your domain. Examples: “If query contains ‘compare’ or ‘versus’ → complex”, “If query mentions multiple time periods → complex”, “If query is <10 words and single entity → simple”.
-
Define retrieval strategies per tier: For your domain, decide: simple queries use k=3, standard use k=5, complex use k=8. Implement conditional logic to activate each strategy.
-
Measure impact: Run for 1 week. Track latency distribution, precision on sampled queries, and query success rates. Compare to baseline.
Production Hardening (2-4 weeks)
-
Train classification model: Collect 300-500 queries from your logs. Manually label each as simple/standard/complex based on what retrieval depth actually worked. Fine-tune a lightweight classifier (e.g., DistilBERT) on this dataset.
-
Implement confidence-based escalation: If classification confidence <75%, bump to next tier automatically. Log these escalations to identify undertrained query types.
-
Add monitoring and alerting: Track classification accuracy, retrieval coverage by tier, and precision by query complexity. Alert if coverage drops below 80%.
-
Implement automatic tier adjustment: Weekly, measure coverage and precision per tier. If coverage drops, incrementally increase k for that tier. If latency degrades, decrease k. Automate this feedback loop.
Advanced Features (Month 2+)
-
Multi-stage retrieval for complex queries: Complex queries trigger entity extraction → graph traversal → temporal filtering → document retrieval. Start with one advanced stage (e.g., graph traversal) and expand.
-
Confidence-based fallback: During generation, if model detects low confidence (fewer than 2 highly relevant documents), automatically re-retrieve with escalated complexity tier.
-
User feedback integration: Let users rate query answers. Correlate feedback with classification tier and retrieval depth. Use to retrain classifier.
The Future: Adaptive Retrieval + Agent-Based RAG
Looking ahead, adaptive retrieval merges with agentic RAG systems. Agents decide not just retrieval depth, but retrieval strategy: “This query needs knowledge graph traversal”, “This one needs temporal aggregation”, “This one needs multi-document reasoning”.
The next frontier isn’t just adapting to query complexity—it’s letting agents dynamically choose retrieval methods based on available data and query intent. That’s where the enterprise RAG systems of 2026-2027 are headed.
For now, adaptive retrieval strategies are the pragmatic win: 25-35% latency improvement, 15-25% precision gains on complex queries, and substantially better handling of heterogeneous query patterns. It’s the difference between a RAG system that works for simple cases and one that works across your entire user base.
Start with rule-based classification. Measure what works. Evolve toward learned models. The principle remains the same: let query complexity dictate retrieval strategy, not the other way around.
If you’re building enterprise RAG and dealing with mixed query patterns, adaptive retrieval isn’t a nice-to-have feature—it’s becoming table stakes. The systems that win in 2026 aren’t the ones with the biggest vector databases; they’re the ones smart enough to ask “Do I even need to retrieve that?” before retrieval begins.
Ready to implement adaptive retrieval in your system? Start by analyzing your query logs. Identify your simple vs. complex queries. Measure current latency and precision. Then implement a simple rule-based classifier and measure again. The data will tell you where adaptive retrieval wins for your use case.


