
Your RAG system is probably leaving 48% of its potential accuracy on the table. Here’s the uncomfortable truth: most teams spend weeks optimizing their embedding models, fine-tuning vector databases, and architecting perfect retrieval pipelines—then deploy without a reranker. It’s like building a world-class filtering system to identify the top 100 candidates for a job, then hiring the first person on the list without a second interview.
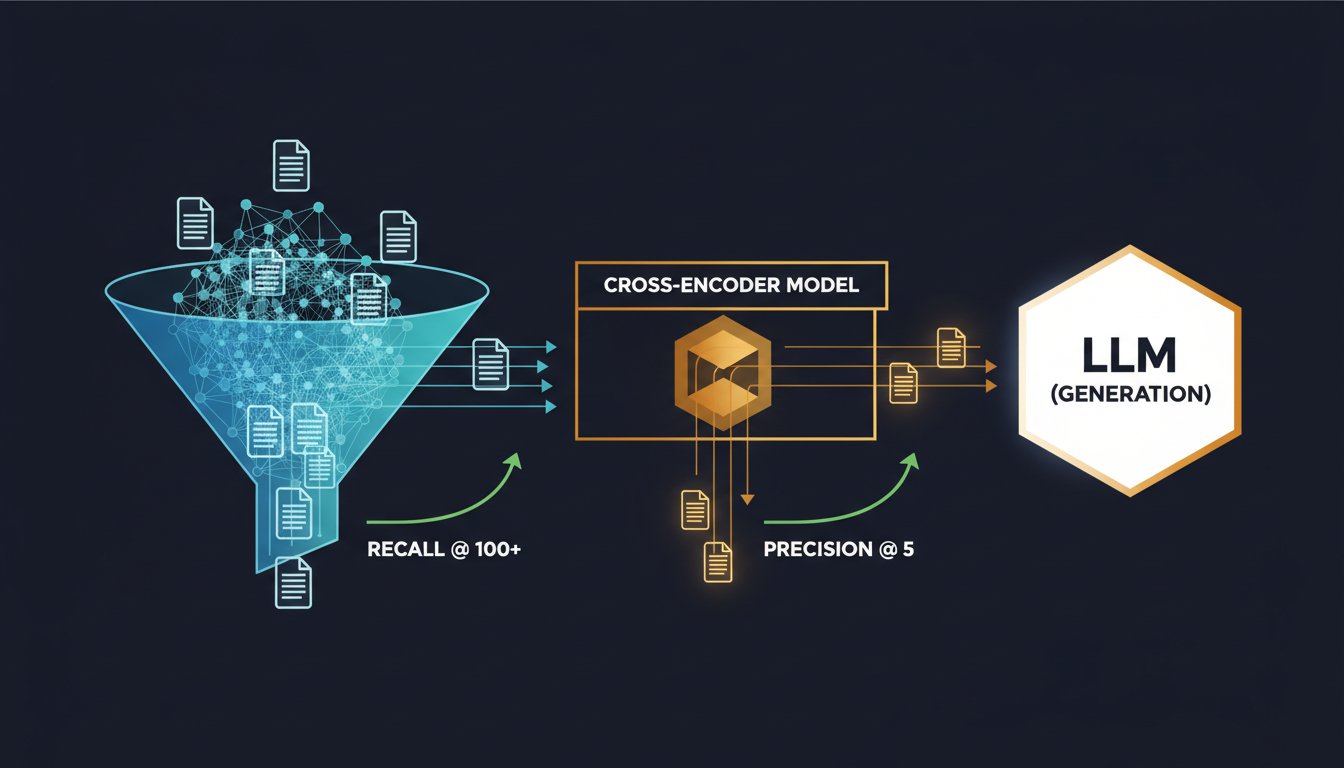
The retrieval stage in RAG systems has a fundamental weakness: it’s optimized for broad recall, not precision. Your dense vector retriever might return 100 contextually relevant documents when your LLM can only meaningfully process 3-5. Without reranking, you’re feeding your language model a haystack when it needs a needle. The consequences ripple through your entire pipeline—hallucinations increase, token consumption explodes, latency bloats, and your production costs skyrocket.
Reranking solves this by introducing a second intelligence layer that sits between retrieval and generation. Instead of relying on a single vector similarity score, rerankers (typically cross-encoder models) evaluate retrieved documents against your specific query, producing a more nuanced relevance ranking. The performance gains are substantial: enterprise implementations report accuracy improvements of 48% when reranking is properly integrated, and token consumption drops proportionally.
But here’s where most implementations fail: teams treat reranking as an afterthought rather than a foundational architecture decision. They pick a reranker based on model size rather than query characteristics, deploy it without understanding the latency-accuracy tradeoff, or build systems that can’t adapt reranking strategies based on query complexity. The result is expensive, slow systems that underdeliver.
This post walks you through the reranking decisions that matter: how to evaluate whether reranking is your bottleneck, how to choose between different reranker architectures, and how to structure your pipeline so reranking actually moves the needle on accuracy and cost.
The Retrieval-Reranking Gap: Why Your Top-K Documents Are Probably Wrong
Vector retrieval operates under a fundamental constraint: it optimizes for finding broadly relevant documents across semantic space. A cosine similarity score of 0.78 between your query embedding and a document embedding tells you the vectors are reasonably aligned—but it doesn’t tell you whether that document actually answers your question.
Consider a practical example: You’re building RAG for a financial compliance system. Your query is “What are the current restrictions on selling to Russian entities?”
Your vector retriever returns documents with these cosine similarity scores:
– Document A (0.82): “Overview of OFAC sanctions lists and general compliance framework”
– Document B (0.81): “Historical Russian sanctions from 2014-2016 (outdated)”
– Document C (0.79): “Current OFAC guidance on Russian entity restrictions (updated Jan 2025)”
Based purely on vector similarity, your LLM receives documents A, B, and C in that order. Your system now has to synthesize outdated information, general frameworks, and current guidance—producing uncertainty and potential hallucinations about current restrictions. A reranker evaluates these same documents against your query’s semantic intent and business context, typically producing the ranking: C > A > B.
This isn’t a marginal improvement. When you have 100+ retrieved documents (standard in enterprise RAG), the probability that your top-5 actually contain the highest-quality answers drops dramatically without reranking. Research shows reranking can improve retrieval accuracy by up to 48%, but the actual impact on your production metrics depends entirely on your implementation.
Why Vector-Only Retrieval Degrades at Scale
Vector similarity is distance-based, meaning it finds documents semantically similar to your query. But semantic similarity ≠ answer quality. A document can be semantically similar to your query yet:
- Contain outdated information (the sanctions example above)
- Be tangentially related but not directly answering (a compliance framework document that mentions Russian sanctions in one paragraph)
- Require multiple hops of reasoning to extract the actual answer (a detailed document that answers your question in the third subsection)
- Conflict with other retrieved documents (different guidance from different time periods)
At small scale (5-10 documents retrieved), these issues are manageable. At enterprise scale (50-200 documents), they become systematic. Your LLM spends token budget synthesizing conflicting information, building context from partially relevant documents, and potentially hallucinating to fill gaps.
Reranking addresses this by introducing a second evaluation layer that measures relevance differently. Instead of embedding-space distance, rerankers evaluate: “Given this specific query and this specific document, how likely is this document to help answer the question accurately?”
How Rerankers Actually Work: Cross-Encoders vs. Everything Else
The reranking landscape has evolved significantly in 2025. Understanding the architectural choices is critical because they directly impact your latency-accuracy tradeoff.
Cross-Encoder Architecture (The Gold Standard)
Cross-encoders take both your query and candidate document as input, process them together, and output a relevance score. This joint processing allows the model to understand complex interactions between query and document—things like negation, temporal relationships, and entity-specific context.
Lead performers in 2025 include:
- Qwen3-Reranker-8B: Industry consensus shows this as the most accurate 2025 reranker, handling complex queries and long documents effectively
- Cohere Rerank 3: Optimized for enterprise search, balancing accuracy with latency (optimized for <100ms per document)
- Jina Reranker: Strong multilingual capabilities, relevant for global enterprises
The tradeoff: Cross-encoders require processing each document individually (latency = documents × model_inference_time). Ranking 100 documents with an 8B cross-encoder on GPU infrastructure might take 2-5 seconds. This is acceptable for search and RAG applications, but not real-time systems.
Listwise Rerankers (The Emerging Alternative)
Listwise rerankers evaluate multiple documents simultaneously, offering better latency characteristics. These are less mature than cross-encoders but show promise for latency-sensitive applications.
The tradeoff: Listwise models often require training on specific data distributions, making them less suitable for enterprises with diverse query types.
Retrieval-Augmented Reranking (The Hybrid Approach)
Some teams use learned ranking models that combine:
- Query-document relevance scores (from cross-encoders)
- Document-document similarity (to avoid redundancy)
- Metadata signals (recency, source authority, citation count)
- Query complexity classifiers (simple queries might not need expensive reranking)
This hybrid approach allows dynamic reranking strategies—expensive deep reranking for complex queries, lightweight filtering for simple ones.
Building a Production Reranking Pipeline: The Decisions That Matter
Decision 1: Is Reranking Your Actual Bottleneck?
Before implementing reranking, measure your baseline retrieval quality. This requires:
Step 1: Establish Ground Truth
– Sample 50-100 of your production queries
– For each query, manually annotate 3-5 documents as “highly relevant,” “relevant,” or “irrelevant”
– This is your evaluation dataset
Step 2: Measure Current Retrieval Performance
– Run your vector retriever on these queries
– Calculate Mean Reciprocal Rank (MRR): the average rank of the first relevant document
– Calculate NDCG@5: normalized discounted cumulative gain, measuring ranking quality
– Calculate Precision@5: what percentage of your top-5 documents are relevant?
Step 3: Identify the Improvement Opportunity
– If Precision@5 < 60%, you have a significant retrieval problem—reranking will help
– If Precision@5 > 85%, your retriever is strong; reranking provides diminishing returns
– If MRR > 0.7 (first relevant document typically in top-3), reranking impact is moderate
This diagnostic approach prevents you from optimizing the wrong component. Many teams add reranking to already-high-quality retrievers and wonder why latency increased with minimal accuracy gains.
Decision 2: Choose Your Reranker Based on Your Query Distribution
Different rerankers excel at different query types:
For simple, direct queries (“What is the current price of commodity X?”):
– Lightweight models: BGE-Reranker-Base (110M) or similar
– Latency: <50ms per document
– Accuracy sacrifice: ~5-8% vs. large models
– Use case: Customer support, FAQ-style systems
For complex, multi-hop queries (“Considering current regulations, what are the supply chain implications for X?”):
– Large models: Qwen3-Reranker-8B or Cohere Rerank 3
– Latency: 100-200ms per document
– Accuracy gain: 15-25% vs. base retrieval
– Use case: Enterprise research, compliance, medical diagnosis support
For mixed query types (most enterprises):
– Implement query complexity classification
– Use lightweight reranker for simple queries
– Escalate to heavy reranker for complex queries
– Typical latency: 30-40ms average across query distribution
Decision 3: Optimize Your Reranking Window
Reranking cost grows linearly with the number of documents you rerank. Your pipeline should look like:
- Dense retrieval: 100-200 documents
- Lightweight filtering: Remove duplicates, low-authority sources, language mismatches → 50-100 documents
- Reranking: Full cross-encoder evaluation → 20-30 documents
- Context window selection: Final documents sent to LLM → 3-5 documents
Most teams skip step 2, feeding all 100+ documents through expensive reranking. This is where cost explodes. A lightweight filtering pass (BM25 redundancy removal, metadata filtering, simple semantic clustering) can cut reranking compute by 50%+ with negligible accuracy loss.
Decision 4: Handle Long Documents Correctly
Cross-encoders have token limits (typically 512 tokens). Long documents must be chunked, but naive chunking destroys context. The reranker might see chunk 3 of a 10-chunk document and give it a low score because it lacks context.
Production approaches:
Approach A: Chunk-Level Reranking
– Rerank individual chunks
– Aggregate scores at document level
– Pro: Fast, works with fixed-size models
– Con: Loses cross-chunk context
Approach B: Sliding Window with Overlap
– Create overlapping chunks (256 tokens with 128-token overlap)
– Rerank each window
– Aggregate scores, considering overlap
– Pro: Preserves local context
– Con: Increases reranking compute by 40-60%
Approach C: Hierarchical Reranking
– First-pass reranker: Scores document summaries or first chunks
– Second-pass reranker (only on top-10): Full document context with longer windows
– Pro: Balances accuracy and cost
– Con: Requires multiple models
For most enterprises, Approach B (sliding window) offers the best accuracy-cost tradeoff.
Real-World Implementation: When Reranking Fails (And How to Fix It)
Production reranking implementations hit three common failure modes:
Failure Mode 1: Latency Explosion
Symptom: Reranking added 2 seconds to your pipeline latency. Your 100ms response time is now 2.1 seconds.
Root cause: You’re reranking 200+ documents with an 8B model on CPU.
Fix:
1. Reduce reranking window (filter to 50 documents before reranking)
2. Use smaller model (4B instead of 8B, sacrificing 3-5% accuracy)
3. Deploy on GPU with batch processing (rank 32 documents in parallel)
4. Implement early stopping (if top-5 documents have clear winners, stop reranking)
Expected outcome: 150-300ms latency, maintaining 80%+ accuracy vs. full reranking
Failure Mode 2: Accuracy Regression Despite Reranking
Symptom: You added reranking, but your RAG accuracy didn’t improve. Sometimes it degraded.
Root cause: Your reranker is domain-misaligned or your vector retriever is actually fine.
Fix:
1. Evaluate reranker on your specific domain (Qwen3 is general-purpose; it might not understand your specialized vocabulary)
2. Consider fine-tuning or domain-adapted rerankers
3. Compare reranker performance against baseline (Precision@5 without reranking)
4. If baseline is already >85%, reranking provides minimal gains; invest elsewhere
Expected outcome: 5-15% accuracy improvement, with diminishing returns above 85% baseline
Failure Mode 3: Context Corruption
Symptom: Your LLM is hallucinating more since you added reranking.
Root cause: Reranker is filtering out documents that contain contradictory information, so the LLM doesn’t see the full picture.
Fix:
1. Always retrieve documents that contradict top results (keep diversity in top-20)
2. Use reranking to order documents, not to filter them completely
3. Implement conflict detection: if reranker gives conflicting documents low scores, investigate why
4. For compliance/medical use cases, explicitly preserve alternative perspectives
Expected outcome: Accurate reranking without losing critical context
The Architecture Decision: Where Does Reranking Live?
Reranking can be implemented at different stages in your pipeline, each with different tradeoffs:
Option 1: Post-Retrieval Reranking (Standard)
Query → Dense Retriever → [100 docs] → Reranker → [20 docs] → LLM
Pros: Simple, doesn’t require retriever modification, works with any retriever
Cons: Ranks documents that probably shouldn’t have been retrieved
Cost: Full reranking cost on full retrieval set
Use when: Retriever quality is acceptable, you need to optimize ranking
Option 2: Iterative Reranking (Advanced)
Query → Dense Retriever → [50 docs] → Lightweight Filter → [30 docs] →
Heavy Reranker → [10 docs] → LLM Context Window Selector → [3 docs] → LLM
Pros: Multi-stage filtering reduces compute, high precision final set
Cons: Complex to implement, harder to debug
Cost: Reduced reranking cost (30 docs instead of 100)
Use when: You need to optimize both accuracy and latency
Option 3: Retriever-Reranker Co-Design (Production-Grade)
Query → Classification (Simple vs. Complex) →
Simple: Lightweight Retriever → BGE Reranker → LLM
Complex: Dense Retriever → Qwen Reranker → LLM
Pros: Query-specific optimization, dynamic resource allocation
Cons: Requires query classification model (adds latency), operational complexity
Cost: Lowest average cost across query distribution
Use when: You have mixed query types, need to optimize cost across production workload
Measuring Reranking Impact: Beyond Accuracy Metrics
Reranking should improve three dimensions of your RAG system:
Dimension 1: Retrieval Quality
- Metric: NDCG@5, MRR, Precision@5
- Target: 15-25% improvement vs. vector-only retrieval
- Measurement: Use your ground truth evaluation set from earlier
- Example: Precision@5 improves from 65% → 80%
Dimension 2: LLM Efficiency
- Metric: Token consumption per query, hallucination rate
- Target: 20-30% reduction in tokens used
- Measurement: Track average tokens in retrieved context; measure hallucination via fact-checking
- Example: Context window drops from 2,000 → 1,500 tokens; hallucination rate drops from 8% → 3%
Dimension 3: Operational Cost
- Metric: Cost per query (retrieval + reranking + LLM inference)
- Target: Cost increase <20% (reranking cost) justified by 25%+ accuracy gain
- Measurement: Track reranking cost separately; calculate ROI
- Example: Reranking adds $0.0001 per query; LLM cost drops from $0.001 → $0.0008; net savings $0.0008 per query
If your reranking implementation doesn’t move all three metrics positively, you likely have an architecture issue.
The Future of Reranking: Emerging Strategies
Multimodal Reranking
2025 is seeing the emergence of rerankers that handle images + text. If your RAG system processes technical documentation with diagrams or medical records with imaging, multimodal reranking becomes critical. Current leaders:
- CLIP-based rerankers (emerging, not yet mature)
- Specialized models for medical imaging + text (research phase)
When to adopt: If your retrieval set includes visual documents and your current reranker ignores them.
Dynamic Reranking with Feedback Loops
Production systems are beginning to implement reinforcement learning approaches where reranking strategies improve based on which documents actually led to accurate LLM outputs. This is research-stage but shows 5-10% accuracy improvements in early implementations.
Agentic Reranking
Instead of static reranking, some architectures use agent-based reranking where an LLM (small, fast) evaluates documents against specific criteria, then chains decisions. This is more explainable but slower—typically used for high-stakes applications (medical, legal, compliance).
Your Next Steps: Building Reranking into Your Pipeline
The reranking landscape in 2025 has matured enough that it’s no longer optional for enterprise RAG systems. Here’s your implementation roadmap:
Week 1-2: Measure your baseline retrieval quality using the evaluation framework above. If Precision@5 > 85%, you might not need reranking—invest in retriever quality instead.
Week 3-4: Select your reranker based on your query distribution. Start with Cohere Rerank 3 (production-ready, good documentation) or Qwen3-Reranker-4B if cost is critical.
Week 5-6: Implement post-retrieval reranking on your dev environment. Measure latency-accuracy tradeoff. Optimize reranking window (start with 50 documents, measure impact of different thresholds).
Week 7-8: Deploy to production with monitoring on latency, accuracy, and cost. Track the three dimensions above weekly.
Ongoing: Establish quarterly evaluation cycles where you re-evaluate your reranker against your evolving query distribution. Reranker performance degrades as your domain vocabulary evolves or new query types emerge.
The teams winning with RAG in 2025 aren’t the ones with the most sophisticated vector databases or the largest embedding models. They’re the ones who’ve systematized the entire pipeline—from retrieval to reranking to context windowing to LLM selection. Reranking is the overlooked multiplier that ties these pieces together.
Start measuring, start optimizing, and you’ll likely find 15-25% accuracy improvements with minimal operational complexity.


